Peer-To-Peer: Harnessing the Power of Disruptive Technologies
Chapter 16: Accountability
Roger Dingledine, Reputation Technologies, Inc., Michael J. Freedman, MIT,
and David Molnar, Harvard University
One year after its meteoric rise to fame, Napster faces a host of problems. The best known of these problems is the lawsuit filed by the Recording Industry Association of America against Napster, Inc. Close behind is the decision by several major universities, including Yale, the University of Southern California, and Indiana University, to ban Napster traffic on their systems, thus depriving the Napster network of some of its highest-bandwidth music servers. The most popular perception is that universities are blocking Napster access out of fear of lawsuit. But there is another reason.
Napster users eat up large and unbounded amounts of bandwidth. By default, when a Napster client is installed, it configures the host computer to serve MP3s to as many other Napster clients as possible. University users, who tend to have faster connections than most others, are particularly effective servers. In the process, however, they can generate enough traffic to saturate a network. It was this reason that Harvard University cited when deciding to allow Napster, yet limit its bandwidth use.
Gnutella, the distributed replacement for Napster, is even worse: not only do downloads require large amounts of bandwidth, but searches require broadcasting to a set of neighboring Gnutella nodes, which in turn forward the request to other nodes. While the broadcast does not send the request to the entire Gnutella network, it still requires bandwidth for each of the many computers queried.
As universities limit Napster bandwidth or shut it off entirely due to bandwidth usage, the utility of the Napster network degrades. As the Gnutella network grows, searching and retrieving items becomes more cumbersome. Each service threatens to dig its own grave--and for reasons independent of the legality of trading MP3s. Instead, the problem is resource allocation.
Problems in resource allocation come up constantly in offering computer services. Traditionally they have been solved by making users accountable for their use of resources. Such accountability in distributed or peer-to-peer systems requires planning and discipline.
Traditional filesystems and communication mediums use accountability to maintain centralized control over their respective resources--in fact, the resources allocated to users are commonly managed by "user accounts." Filesystems use quotas to restrict the amount of data that users may store on the systems. ISPs measure the bandwidth their clients are using--such as the traffic generated from a hosted web site--and charge some monetary fee proportional to this amount.
Without these controls, each user has an incentive to squeeze all the value out of the resource in order to maximize personal gain. If one user has this incentive, so do all the users.
Biologist Garrett Hardin labeled this economic plight the "tragedy of the commons."[1] The "commons" (originally a grazing area in the middle of a village) is any resource shared by a group of people: it includes the air we breathe, the water we drink, land for farming and grazing, and fish from the sea. The tragedy of the commons is that a commonly owned resource will be overused until it is degraded, as all agents pursue self-interest first. Freedom in a commons brings ruin to all; in the end, the resource is exhausted.
We can describe the problem by further borrowing from economics and political science. Mancur Olson explained the problem of collective actions and public goods as follows:
"[U]nless the number of individuals in a group is quite small, or unless there is coercion or some other special device to make individuals act in their common interest, rational, self-interested individuals will not act to achieve their common or group interests.[2]
The usual solution for commons problems is to assign ownership to the resource. This ownership allows a party to profit from the resource, thus providing the incentive to care for it. Most real-world systems take this approach with a fee-for-service business model.
Decentralized peer-to-peer systems have similar resource allocation and protection requirements. The total storage or bandwidth provided by the sum of all peers is still finite. Systems need to protect against two main areas of attack:
- Denial of service (DoS) attacks
- Overload a system's bandwidth or processing ability, causing the loss of service of a particular network service or all network connectivity. For example, a web site accessed millions of times may show "503" unavailability messages or temporarily refuse connections.
- Storage flooding attacks
- Exploit a system by storing a disproportionally large amount of data so that no more space is available for other users.
As the Napster and Gnutella examples show, attacks need not be malicious. System administrators must be prepared for normal peaks in activity, accidental misuse, and the intentional exploitation of weaknesses by adversaries. Most computers that offer services on a network share these kinds of threats.
Without a way to protect against the tragedy of the commons, collaborative networking rests on shaky ground. Peers can abuse the protocol and rules of the system in any number of ways, such as the following:
- Providing corrupted or low-quality information
- Reneging on promises to store data
- Going down during periods when they are needed
- Claiming falsely that other peers have abused the system in these ways
These problems must be addressed before peer-to-peer systems can achieve lasting success. Through the use of various accountability measures, peer-to-peer systems--including systems that offer protection for anonymity--may continue to expand as overlay networks through the existing Internet.
This chapter focuses on types of accountability that collaborative systems can use to protect against resource allocation attacks. The problem of accountability is usually broken into two parts:
- Restricting access
- Each computer system tries to limit its users to a certain number of connections, a certain quantity of data that can be uploaded or downloaded, and so on. We will describe the technologies for doing this that are commonly called micropayments, a useful term even though at first it can be misleading. (They don't necessarily have to involve an exchange of money, or even of computer resources.)
- Selecting favored users
- This is normally done through maintaining a reputation for each user the system communicates with. Users with low reputations are allowed fewer resources, or they are mistrusted and find their transactions are rejected.
The two parts of the solution apply in different ways but work together to create accountability. In other words, a computer system that is capable of restricting access can then use a reputation system to grant favored access to users with good reputations.
The difficulty of accountability
In simple distributed systems, rudimentary accountability measures are often sufficient. If the list of peers is generally static and all are known to each other by hostname or address, misbehavior on anyone's part leads to a permanent bad reputation. Furthermore, if the operators of a system are known, preexisting mechanisms such as legal contracts help ensure that systems abide by protocol.
In the real world, these two social forces--reputation and law--have provided an impetus for fair trade for centuries. Since the earliest days of commerce, buyers and merchants have known each others' identities, at first through the immediacy of face-to-face contact, and later through postal mail and telephone conversations. This knowledge has allowed them to research the past histories of their trading partners and to seek legal reprisal when deals go bad. Much of today's e-commerce uses a similar authentication model: clients (both consumers and businesses) purchase items and services from known sources over the Internet and the World Wide Web. These sources are uniquely identified by digital certificates, registered trademarks, and other addressing mechanisms.
Peer-to-peer technology removes central control of such resources as communication, file storage and retrieval, and computation. Therefore, the traditional mechanisms for ensuring proper behavior can no longer provide the same level of protection.
Special problems posed by peer-to-peer systems
Peer-to-peer systems have to treat identity in special ways for several reasons:
- The technology makes it harder to uniquely and permanently identify peers and their operators. Connections and network maps might be transient. Peers might be able to join and leave the system. Participants in the system might wish to hide personal identifying information.
- Even if users have an identifying handle on the peer they're dealing with, they have no idea who the peer is and no good way to assess its history or predict its performance.
- Individuals running peer-to-peer services are rarely bound by contracts, and the cost and time delay of legal enforcement would generally outweigh their possible benefit.
We choose to deal with these problems--rather than give up and force everyone on to a centralized system with strong user identification--to pursue two valuable goals on the Internet: privacy and dynamic participation.
Privacy is a powerfully appealing goal in distributed systems, as discussed in Chapter 12, Free Haven. The design of many such systems features privacy protection for people offering and retrieving files.
Privacy for people offering files requires a mechanism for inserting and retrieving documents either anonymously or pseudonymously.[3] Privacy for people retrieving files requires a means to communicate--via email, Telnet, FTP, IRC, a web client, etc.--while not divulging any information that could link the user to his or her real-world persona.[4]
Dynamic participation has both philosophical and practical advantages. The Internet's loosely connected structure and explosive growth suggest that any peer-to-peer system must be similarly flexible and dynamic in order to be scalable and sustain long-term use. Similarly, the importance of ad hoc networks will probably increase in the near future as wireless connections get cheaper and more ubiquitous. A peer-to-peer system should therefore let peers join and leave smoothly, without impacting functionality. This design also decreases the risk of systemwide compromise as more peers join the system. (It helps if servers run a variety of operating systems and tools, so that a single exploit cannot compromise most of the servers at once.)
Peer-to-peer models and their impacts on accountability
There are many different models for peer-to-peer systems. As the systems become more dynamic and diverge from real-world notions of identity, it becomes more difficult to achieve accountability and protect against attacks on resources.
The simplest type of peer-to-peer system has two main characteristics. First, it contains a fairly static list of servers; additions and deletions are rare and may require manual intervention. Second, the identities of the servers (and to some extent their human operators) are known, generally by DNS hostname or static IP host address. Since the operators can be found, they may have a legal responsibility or economic incentive--leveraged by the power of reputation--to fulfill the protocols according to expectation.
An example of such a peer-to-peer system is the Mixmaster remailer. A summary of the system appears in Chapter 7, Mixmaster Remailers. The original Mixmaster client software was developed by Lance Cottrell and released in 1995.[5] Currently, the software runs on about 30 remailer nodes, whose locations are published to the newsgroup alt.privacy.anon-server and at web sites such as http://efga.org.[6] The software itself can be found at http://mixmaster.anonymizer.com.
Remailer nodes are known by hostname and remain generally fixed. While anybody can start running a remailer, the operator needs to spread information about her new node to web pages that publicize node statistics, using an out-of-band channel (meaning that something outside the Mixmaster system must be used--most of the time, manually sent email). The location of the new node is then manually added to each client's software configuration files. This process of manually adding new nodes leads to a system that remains generally static. Indeed, that's why there are so few Mixmaster nodes.
A slightly more complicated type of peer-to-peer system still has identified operators but is dynamic in terms of members. That is, the protocol itself has support for adding and removing participating servers. One example of such a system is Gnutella. It has good support for new users (which are also servers) joining and leaving the system, but at the same time, the identity and location of each of these servers is generally known through the hosts list, which advertises existing hosts to new ones that wish to join the network. These sorts of systems can be very effective, because they're generally easy to deploy (there's no need to provide any real protection against people trying to learn the identity of other participants), while at the same time they allow many users to freely join the system and donate their resources.
Farther still along the scale of difficulty lie peer-to-peer systems that have dynamic participants and pseudonymous servers. In these systems, the actual servers that store files or proxy communication live within a digital fog that conceals their geographic locations and other identifying features. Thus, the mapping of pseudonym to real-world identity is not known. A given pseudonym may be pegged with negative attributes, but a user can just create a new pseudonym or manage several at once. Since a given server can simply disappear at any time and reappear as a completely new entity, these sorts of designs require a micropayment system or reputation system to provide accountability on the server end. An example of a system in this category is the Free Haven design: each server can be contacted via a remailer reply block and a public key, but no other identifying features are available.
The final peer-to-peer model on this scale is a dynamic system with fully anonymous operators. A server that is fully anonymous lacks even the level of temporary identity provided by a pseudonymous system like Free Haven. Since an anonymous peer's history is by definition unknown, all decisions in an anonymous system must be based only on the information made available during each protocol operation. In this case, peers cannot use a reputation system, since there is no real opportunity to establish a profile on any server. This leaves a micropayment system as the only reasonable way to establish accountability. On the other hand, because the servers themselves have no long-term identities, this may limit the number of services or operations such a system could provide. For instance, such a system would have difficulty offering long-term file storage and backup services.
Purposes of micropayments and reputation systems
The main goal of accountability is to maximize a server's utility to the overall system while minimizing its potential threat. There are two ways to minimize the threat.
- One approach is to limit our risk (in bandwidth used, disk space lost, or whatever) to an amount roughly equivalent to our benefit from the transaction. This suggests the fee-for-service or micropayment model mentioned at the beginning of the chapter.
- The other approach is to make our risk proportional to our trust in the other parties. This calls for a reputation system.
In the micropayment model, a server makes decisions based on fairly immediate information. Payments and the value of services are generally kept small, so that a server only gambles some small amount of lost resources for any single exchange. If both parties are satisfied with the result, they can continue with successive exchanges. Therefore, parties require little prior information about each other for this model, as the risk is small at any one time. As we will see later in this chapter, where we discuss real or existing micropayment systems, the notion of payment might not involve any actual currency or cash.
In the reputation model, for each exchange a server risks some amount of resources proportional to its trust that the result will be satisfactory. As a server's reputation grows, other nodes become more willing to make larger payments to it. The micropayment approach of small, successive exchanges is no longer necessary.
Reputation systems require careful development, however, if the system allows impermanent and pseudonymous identities. If an adversary can gain positive attributes too easily and establish a good reputation, she can damage the system. Worse, she may be able to "pseudospoof," or establish many seemingly distinct identities that all secretly collaborate with each other.
Conversely, if a well-intentioned server can incur negative points easily from short-lived operational problems, it can lose reputation too quickly. (This is the attitude feared by every system administrator: "Their web site happened to be down when I visited, so I'll never go there again.") The system would lose the utility offered by these "good" servers.
As we will see later in this chapter, complicated protocols and calculations are required for both micropayments and reputation systems. Several promising micropayment systems are in operation, while research on reputation systems is relatively young. These fields need to develop ways of checking the information being transferred, efficient tests for distributed computations, and, more broadly, some general algorithms to verify behavior of decentralized systems.
There is a third way to handle the accountability problem: ignore the issue and engineer the system simply to survive some faulty servers. Instead of spending time on ensuring that servers fulfill their function, leverage the vast resources of the Internet for redundancy and mirroring. We might not know, or have any way to find out, if a server is behaving according to protocol (i.e., whether that server is storing files and responding to file queries, forwarding email or other communications upon demand, and correctly computing values or analyzing data). Instead, if we replicate the file or functionality through the system, we can ensure that the system works correctly with high probability, despite misbehaving components. This is the model used by Napster, along with some of the systems discussed in this book, such as Freenet and Gnutella.
In general, the popular peer-to-peer systems take a wide variety of approaches to solving the accountability problem. For instance, consider the following examples:
- Freenet dumps unpopular data on the floor, so people flooding the system with unpopular data are ultimately ignored. Popular data is cached near the requester, so repeated requests won't traverse long sections of the network.
- Gnutella doesn't "publish" documents anywhere except on the publisher's computer, so there's no way to flood other systems. (This has a great impact on the level of anonymity actually offered.)
- Publius limits the submission size to 100K. (It remains to be seen how successful this will be; they recognize it as a problem.)
- Mojo Nation uses micropayments for all peer-to-peer exchanges.
- Free Haven requires publishers to provide reliable space of their own if they want to insert documents into the system. This economy of reputation tries to ensure that people donate to the system in proportion to how much space they use.
Junk mail as a resource allocation problem
The familiar problem of junk email (known more formally as unsolicited commercial email, and popularly as spam) yields some subtle insights into resource allocation and accountability. Junk mail abuses the unmetered nature of email and of Internet bandwidth in general. Even if junk email achieves only an extremely small success rate, the sender is still successful because the cost of sending each message is essentially zero.
Spam wastes both global and individual resources. On a broad scale, it congests the Internet, wasting bandwidth and server CPU cycles. On a more personal level, filtering and deleting spam can waste an individual's time (which, collectively, can represent significant person-hours). Users also may be faced with metered connection charges, although recent years have seen a trend toward unmetered service and always-on access.
Even though the motivations for junk email might be economic, not malicious, senders who engage in such behavior play a destructive role in "hogging" resources. This is a clear example of the tragedy of the commons.
Just as some environmental activists suggest curbing pollution by making consumers pay the "real costs" of the manufacturing processes that cause pollution, some Internet developers are considering ways of stopping junk email by placing a tiny burden on each email sent, thus forcing the sender to balance the costs of bulk email against the benefits of responses. The burden need not be a direct financial levy; it could simply require the originator of the email to use significant resources. The cost of an email message should be so small that it wouldn't bother any individual trying to reach another; it should be just high enough to make junk email unprofitable. We'll examine such micropayment schemes later in this chapter.
We don't have to change the infrastructure of the Internet to see a benefit from email micropayments. Individuals can adopt personal requirements as recipients. But realistically, individual, nonstandard practices will merely reduce the usability of email. Although individuals adopting a micropayment scheme may no longer be targeted, the scheme would make it hard for them to establish relationships with other Internet users, while junk emailers would continue to fight over the commons.
Pseudonymity and its consequences
Many, if not most, of the services on the Internet today do not deal directly with legal identities. Instead, web sites and chat rooms ask their users to create a handle or pseudonym by which they are known while using that system. These systems should be distinguished from those that are fully anonymous; in a fully anonymous system, there is no way to refer to the other members of the system.
Problems with pseudospoofing and possible defenses
The most important difficulty caused by pseudonymity is pseudospoofing. A term first coined by L. Detweiler on the Cypherpunks mailing list, pseudospoofing means that one person creates and controls many phony identities at once. This is a particularly bad loophole in reputation systems that blithely accept input from just any user, like current web auction sites. An untrustworthy person can pseudospoof to return to the system after earning a bad reputation, and he can even create an entire tribe of accounts that pat each other on the back. Pseudospoofing is a major problem inherent in pseudonymous systems.
Lots of systems fail in the presence of pseudospoofing. Web polls are one example; even if a web site requires registration, it's easy for someone to simply register and then vote 10, 15, or 1,500 times. Another example is a free web hosting site, such as GeoCities, which must take care to avoid someone registering under six or seven different names to obtain extra web space.
Pseudospoofing is hard in the real world, so most of us don't think about it. After all, in the real world, changing one's appearance and obtaining new identities is relatively rare, spy movies to the contrary. When we come online, we bring with us the assumptions built up over a lifetime of dealing with people who can be counted on to be the "same person" next time we meet them. Pseudospoofing works, and works so well, because these assumptions are completely unjustified online. As shown by the research of psychologist Sherry Turkle and others, multiple identities are common in online communities.
So what can we do about pseudospoofing? Several possibilities present themselves:
- Abandon pseudonymous systems entirely. Require participants in a peer-to-peer system to prove conclusively who they are. This is the direction taken by most work on Public Key Infrastructures (PKIs), which try to tie each online users to some legal identity. Indeed, VeriSign used to refer to its digital certificates as "driver's licenses for the information superhighway."
- Identity does not imply accountability. For example, if a misbehaving user is in a completely different jurisdiction, other users may know exactly who he or she is and yet be unable to do anything about it. Even if they are in the same jurisdiction, the behavior may be perfectly legal, just not very nice.
- Accountability is possible even in pseudonymous systems. This point will be developed at length in the rest of this chapter.
- The problem with pseudospoofing is not that someone acts under a "fake" name, but that someone acts under more than one name. If we could somehow build a system that ensured that every pseudonym was controlled by a distinct person, a reputation system could handle the problem.
- Allow pseudonyms, but ensure that all participants are distinct entities. This is all that is strictly necessary to prevent pseudospoofing. Unfortunately, it tends to be not much easier than asking for everyone's legal identity.
- Monitor user behavior for evidence of pseudospoofing. Remove or "expose" accounts that seem to be controlled by the same person. The effectiveness of this approach varies widely with the application. It also raises privacy concerns for users.
- Make pseudospoofing unprofitable. Give new accounts in a system little or no resources until they can prove themselves by doing something for the system. Make it so expensive for an adversary to prove itself multiple times that it has no inclination to pseudospoof. This is the approach taken by the Free Haven project, which deals with new servers by asking them to donate resources to the good of the system as a whole.
This approach has a strong appeal. After all, why should people be allowed to "hide" behind a pseudonym? And how can we possibly have accountability without someone's real identity?
Unfortunately, this approach is unnecessary, unworkable, and in some cases undesirable. It's unnecessary for at least three reasons:
Furthermore, absolute authentication is unworkable because it requires verifying the legal identities of all participants. On today's Internet, this is a daunting proposition. VeriSign and other PKI companies are making progress in issuing their "digital driver's licenses," but we are a far cry from that end. In addition, one then has to trust that the legal identities have not themselves been fabricated. Verification can be expensive and leaves a system that relies on it open to attack if it fails.
Finally, this proposed solution is undesirable because it excludes users who either cannot or will not participate. International users of a system may not have the same ways of verifying legal identity. Other users may have privacy concerns.
All of these alternatives are just rules of thumb. Each of them might help us combat the problems of pseudospoofing, but it's hard to reach a conclusive solution. We'll return to possible technical solutions later in this chapter when we describe the Advogato system.
Reputation for sale--SOLD!
Pseudonymous systems are based on the assumption that each pseudonym is controlled by the same entity for the duration of the system. That is, the adversary's pseudonyms stay controlled by the adversary, and the good guys' pseudonyms stay controlled by the good guys.
What happens if the adversary takes control of someone who already has a huge amount of trust or resources in the system? Allowing accounts to change hands can lead to some surprising situations.
The most prevalent example of this phenomenon comes in online multiplayer games. One of the best-known such games is Ultima Online. Players gallivant around the world of Brittania, completing quests, fighting foes, and traipsing around dungeons, in the process accumulating massive quantities of loot. Over the course of many, many hours, a player can go from a nobody to the lord and master of his own castle. Then he can sell it all to someone else.
Simply by giving up his username and password, an Ultima Online player can transfer ownership of his account to someone else. The new owner obtains all the land and loot that belonged to the old player. More importantly, she obtains the reputation built up by the old player. The transfer can be carried out independently of the game; no one need ever know that it happened. As far as anyone else knows, the game personality is the same person. Until the new owner does something "out of character," or until the news spreads somehow, there is no way to tell that a transfer has occurred.
This has led to a sort of cottage industry in trading game identities for cash online. Ultima Online game identities, or "avatars," can be found on auction at eBay. Other multiplayer online games admit the occurrence of similar transactions. Game administrators can try to forbid selling avatars, but as long as it's just a matter of giving up a username and password, it will be an uphill battle.
The point of this example is that reputations and identities do not bind as tightly to people online as they do in the physical world. Reputations can be sold or stolen with a single password. While people can be coerced or "turned" in the physical world, it's much harder. Once again, the assumptions formed in the physical world turn out to be misleading online.
One way of dealing with this problem is to embed an important piece of information, such as a credit card number, into the password for an account. Then revealing the password reveals the original user's credit card number as well, creating a powerful incentive not to trade away the password. The problem is that if the password is ever accidentally compromised, the user now loses not just the use of his or her account, but the use of a credit card as well.
Another response is to make each password valid only for a certain number of logins; to get a new password, the user must prove that he is the same person who applied for the previous password. This does not stop trading passwords, however--it just means the "original" user must hang around to renew the password each time it expires.
Common methods for dealing with flooding and DoS attacks
We've seen some examples of resource allocation problems and denial of service attacks. These problems have been around for a long while in various forms, and there are several widespread strategies for dealing with them. We'll examine them in this section to show that even the most common strategies are subject to attack--and such attacks can be particularly devastating to peer-to-peer systems.
Caching and mirroring
One of the simplest ways to maintain data availability is to mirror it. Instead of hosting data on one machine, host it on several. When one machine becomes congested or goes down, the rest are still available. Popular software distributions like the Perl archive CPAN and the GNU system have a network of mirror sites, often spread across the globe to be convenient to several different nations at once.
Another common technique is caching: If certain data is requested very often, save it in a place that is closer to the requester. Web browsers themselves cache recently visited pages.
Simple to understand and straightforward to implement, caching and mirroring are often enough to withstand normal usage loads. Unfortunately, an adversary bent on a denial of service attack can target mirrors one by one until all are dead.
Active caching and mirroring
Simple mirroring is easy to do, but it also has drawbacks. Users must know where mirror sites are and decide for themselves which mirror to use. This is more hassle for users and inefficient to boot, as users do not generally know their networks well enough to pick the fastest web site. In addition, users have little idea of how loaded a particular mirror is; if many users suddenly decide to visit the same mirror, they may all receive worse connections than if they had been evenly distributed across mirror sites.
In 1999, Akamai Technologies became an overnight success with a service that could be called active mirroring. Web sites redirect their users to use special "Akamaized" URLs. These URLs contain information used by Akamai to dynamically direct the user to a farm of Akamai web servers that is close to the user on the network. As the network load and server loads change, Akamai can switch users to the best server farm of the moment.
For peer-to-peer systems, an example of active caching comes in the Freenet system for file retrieval. In Freenet, file requests are directed to a particular server, but this server is in touch with several other servers. If the initial server has the data, it simply returns the data. Otherwise, it forwards the request to a neighboring server which it believes more capable of answering the request, and keeps a record of the original requester's address. The neighboring server does the same thing, creating a chain of servers. Eventually the request reaches a server that has the data, or it times out. If the request reaches a server that has the data, the server sends the data back through the chain to the original requester. Every server in the chain, in addition, caches a copy of the requested data. This way, the next time the data is requested, the chance that the request will quickly hit a server with the data is increased.
Active caching and mirroring offer more protection than ordinary caching and mirroring against the "Slashdot effect" and flooding attacks. On the other hand, systems using these techniques then need to consider how an adversary could take advantage of them. For instance, is it possible for an adversary to fool Akamai into thinking a particular server farm is better- or worse-situated than it actually is? Can particular farms be targeted for denial of service attacks? In Freenet, what happens if the adversary spends all day long requesting copies of the complete movie Lawrence of Arabia and thus loads up all the local servers to the point where they have no room for data wanted by other people? These questions can be answered, but they require thought and attention.
For specific answers on a specific system, we might be able to answer these questions through a performance and security analysis. For instance, Chapter 14, Performance, uses Freenet and Gnutella as models for performance analysis. Here, we can note two general points about how active caching reacts to adversaries.
First, if the cache chooses to discard data according to which data was least recently used, the cache is vulnerable to an active attack. An adversary can simply start shoving material into the cache until it displaces anything already there. In particular, an adversary can simply request that random bits be cached. Active caching systems whose availability is important to their users should have some way of addressing this problem.
Next, guaranteeing service in an actively cached system with multiple users on the same cache is tricky. Different usage patterns fragment the cache and cause it to be less useful to any particular set of users. The situation becomes more difficult when adversaries enter the picture: by disrupting cache coherency on many different caches, an adversary may potentially wreak more havoc than by mounting a denial of service attack on a single server.
One method for addressing both these problems is to shunt users to caches based on their observed behavior. This is a radical step forward from a simple least-recently-used heuristic. By using past behavior to predict future results, a cache has the potential to work more efficiently. This past behavior can be considered a special kind of reputation, a topic we'll cover in general later in this chapter.
But systems can also handle resource allocation using simpler and relatively well tested methods involving micropayments. In the next section, we'll examine some of them closely.
Micropayment schemes
Accountability measures based on micropayments require that each party offer something of value in an exchange. Consider Alice and Bob, both servers in a peer-to-peer system that involves file sharing or publishing. Alice may be inserting a document into the system and want Bob to store it for her. Alternatively, Alice may want Bob to anonymously forward some email or real-time Internet protocol message for her. In either case, Alice seeks some resource commodity--storage and bandwidth, respectively--from Bob. In exchange, Bob asks for a micropayment from Alice to protect his resources from overuse.
There are two main flavors of micropayments schemes. Schemes of the first type do not offer Bob any real redeemable value; their goal is simply to slow Alice down when she requests resources from Bob. She pays with a proof of work (POW), showing that she performed some computationally difficult problem. These payments are called nonfungible, because Bob cannot turn around and use them to pay someone else. With the second type of scheme, fungible micropayments, Bob receives a payment that holds some intrinsic or redeemable value. The second type of payment is commonly known as digital cash. Both of these schemes may be used to protect against resource allocation attacks.
POWs can prevent communication denial of service attacks. Bob may require someone who wishes to connect to submit a POW before he allocates any non-trivial resources to communication. In a more sophisticated system, he may start charging only if he detects a possible DoS attack. Likewise, if Bob charges to store data, an attacker needs to pay some (prohibitively) large amount to flood Bob's disk space. Still, POWs are not a perfect defense against an attacker with a lot of CPU capacity; such an attacker could generate enough POWs to flood Bob with connection requests or data.
Varieties of micropayments or digital cash
The difference between micropayments and digital cash is a semantic one. The term "micropayment" has generally been used to describe schemes using small-value individual payments. Usually, Alice will send a micropayment for some small, incremental use of a resource instead of a single large digital cash "macropayment" for, say, a month's worth of service. We'll continue to use the commonly accepted phrase "micropayment" in this chapter without formally differentiating between the two types, but we'll describe some common designs for each type.
Digital cash may be either anonymous or identified. Anonymous schemes do not reveal Alice's identity to Bob or the bank providing the cash, while identified spending schemes expose her information. Hybrid approaches can be taken: Alice might remain anonymous to Bob but not to the bank or anonymous to everybody yet traceable. The latter system is a kind of pseudonymity; the bank or recipient might be able to relate a sequence of purchases, but not link them to an identity.
No matter the flavor of payment--nonfungible, fungible, anonymous, identified, large, or small--we want to ensure that a malicious user can't commit forgery or spend the same coin more than once without getting caught. A system of small micropayments might not worry about forgeries of individual micropayments, but it would have to take steps to stop large-scale, multiple forgeries.
Schemes identifying the spender are the digital equivalent of debit or credit cards. Alice sends a "promise of payment" that will be honored by her bank or financial institution. Forgery is not much of a problem here because, as with a real debit card, the bank ensures that Alice has enough funds in her account to complete the payment and transfers the specified amount to Bob. Unfortunately, though, the bank has knowledge of all of Alice's transactions.
Anonymous schemes take a different approach and are the digital equivalent of real cash. The electronic coin itself is worth some dollar amount. If Alice loses the coin, she's lost the money. If Alice manages to pay both Bob and Charlie with the same coin and not get caught, she's successfully double-spent the coin.
In the real world, government mints use special paper, microprinting, holograms, and other technologies to prevent forgery. In a digital medium, duplication is easy: just copy the bits! We need to find alternative methods to prevent this type of fraud. Often, this involves looking up the coin in a database of spent coins. Bob might have a currency unique to him, so that the same coin couldn't be used to pay Charlie. Or coins might be payee-independent, and Bob would need to verify with the coin's issuing "mint" that it has not already been spent with Charlie.
With this description of micropayments and digital cash in mind, let's consider various schemes.
Nonfungible micropayments
Proofs of work were first advocated by Cynthia Dwork and Moni Naor[7] in 1992 as "pricing via processing" to handle resource allocation requests.
The premise is to make a user compute a moderately hard, but not intractable, computation problem before gaining access to some resource. It takes a long time to solve the problem but only a short time to verify that the user found the right solution. Therefore, Alice must perform a significantly greater amount of computational work to solve the problem than Bob has to perform to verify that she did it.
Dwork and Naor offer their system specifically as a way to combat electronic junk mail. As such, it can impose a kind of accountability within a distributed system.
To make this system work, a recipient refuses to receive email unless a POW is attached to each message. The POW is calculated using the address of the recipient and must therefore be generated specifically for the recipient by the sender. These POWs serve as a form of electronic postage stamp, and the way the recipient's address is included makes it trivial for the recipient to determine whether the POW is malformed. Also, a simple lookup in a local database can be used to check whether the POW has been spent before.
The computational problem takes some amount of time proportional to the time needed to write the email and small enough that its cost is negligible for an individual user or a mail distribution list. Only unsolicited bulk mailings would spend a large amount of computation cycles to generate the necessary POWs.
Recipients can also agree with individual users or mail distribution lists to use an access control list ("frequent correspondent list") so that some messages do not require a POW. These techniques are useful for social efficiency: if private correspondence instead costs some actual usage fee, users may be less likely to send email that would otherwise be beneficial, and the high bandwidth of the electronic medium may be underutilized.
Dwork and Naor additionally introduced the idea of a POW with a trap door: A function that is moderately hard to compute without knowledge of some secret, but easy to compute given this secret. Therefore, central authorities could easily generate postage to sell for prespecified destinations.
Extended types of nonfungible micropayments
Hash cash, designed by Adam Back in late 1997,[8] is an alternative micropayment scheme that is also based on POWs. Here, Bob calculates a hash or digest, a number that can be generated easily from a secret input, but that cannot be used to guess the secret input. (See Chapter 15, Trust.) Bob then asks Alice to guess the input through a brute-force calculation; he can set how much time Alice has to "pay" by specifying how many bits she must guess. Typical hashes used for security are 128 bits or 160 bits in size. Finding another input that will produce the entire hash (which is called a "collision") requires a prohibitive amount of time.
Instead, Bob requires Alice to produce a number for which some of the low-order bits match those of the hash. If we call this number of bits k, Bob can set a very small k to require a small payment or a larger k to require a larger payment. Formally, this kind of problem is called a "k-bit partial hash collision."
For example, the probability of guessing a 17-bit collision is 2-17; this problem takes approximately 65,000 tries on average. To give a benchmark for how efficient hash operations are, in one test, our Pentium-III 800 MHz machine performed approximately 312,000 hashes per second.
Hash cash protects against double-spending by using individual currencies. Bob generates his hash from an ID or name known to him alone. So the hash cash coins given to Bob must be specific to Bob, and he can immediately verify their validity against a local spent-coin database.
Another micropayment scheme based on partial hash collisions is client puzzles, suggested by researchers Ari Juels and John Brainard of RSA Labs.[9] Client puzzles were introduced to provide a cryptographic countermeasure against connection depletion attacks, whereby an attacker exhausts a server's resources by making a large number of connection requests and leaving them unresolved.
When client puzzles are used, a server accepts connection requests as usual. However, when it suspects that it is under attack, marked by a significant rise in connection requests, it responds to requests by issuing each requestor a puzzle: A hard cryptographic problem based on the current time and on information specific to the server and client request.[10]
Like hash cash, client puzzles require that the client find some k-bit partial hash collisions. To decrease the chance that a client might just guess the puzzle, each puzzle could optionally be made up of multiple subpuzzles that the client must solve individually. Mathematically, a puzzle is a hash for which a client needs to find the corresponding input that would produce it.[11]
Nonparallelizable work functions
Both of the hash collision POW systems in the previous section can easily be solved in parallel. In other words, a group of n machines can solve each problem in 1/n the amount of time as a single machine. Historically, this situation is like the encryption challenges that were solved relatively quickly by dividing the work among thousands of users.
Parallel solutions may be acceptable from the point of view of accountability. After all, users still pay with the same expected amount of burnt CPU cycles, whether a single machine burns m cycles, or n machines burn m cycles collectively. But if the goal of nonfungible micropayments is to ensure public access to Bob's resources, parallelizable schemes are weak because they can be overwhelmed by distributed denial of service attacks.
Let's actually try to make Alice wait for a fixed period between two transactions, in order to better protect Bob's resources. Consider a "proof of time": we desire a client to spend some amount of time, as opposed to work, to solve a given problem. An example is MIT's LCS35 Time Capsule Crypto-Puzzle. The time capsule, sealed in 1999, will be opened either after 35 years or when the supplied cryptographic problem is solved, whichever comes first. The problem is designed to foil any benefit of parallel or distributed computing. It can be solved only as quickly as the fastest single processor available.
Time-lock puzzles, such as the LCS35 time capsule, were first presented by Ron Rivest, Adi Shamir, and David Wagner.[12] These types of puzzles are designed to be "intrinsically" or "inherently" sequential in nature. The problem LCS35 used to compute is:
22t mod n
where n is the product of two large primes p and q, and t can be arbitrarily chosen to set the difficulty of the puzzle. This puzzle can be solved only by performing t successive squares modulo n. There is no known way to speed up this calculation without knowing the factorization of n. The reason is the same reason conventional computer encryption is hard to break: there is no existing method for finding two primes when only their product is known.
It's worth noting in passing that the previous construction is not proven to be nonparallelizable. Besides the product-of-two-primes problem, its security rests on no one knowing how to perform the repeated modular squaring in parallel. This problem is tied up with the "P vs. NC" problem in computational complexity theory and is outside the scope of this chapter. Similar to the better known "P vs. NP" problem, which concerns the question, "Which problems are easy?" the P vs. NC problem asks, "Which problems are parallelizable?"[13]
Fungible micropayments
All of the micropayment schemes we have previously described are nonfungible. While Alice pays Bob for resource use with some coin that represents a proof of work, he cannot redeem this token for something of value to him. While this micropayment helps prevent DoS and flooding attacks, there's no measure of "wealth" in the system. Bob has no economic incentive to engage in this exchange.
Nonfungible micropayments are better suited for ephemeral resources, like TCP connections, than they are for long-term resources like data storage. Consider an attacker who wants to make a distributed datastore unusable. If an attacker is trying to fill up a system's storage capacity and is allowed to store data for a long time, the effects of DoS attacks can be cumulative. This is because the attacker can buy more and more space on the system as time goes on.
If micropayments just use up CPU cycles and cannot be redeemed for something of value, an attacker can slowly nibble at resources, requesting a megabyte now and then as it performs enough work to pay for the space. This can continue, bit by bit, until the attacker controls a large percentage of the total. Furthermore, the victim is unable to use these payments in exchange for other peers' resources, or alternatively to purchase more resources.
Enter redeemable payments. This compensation motivates users to donate resources and fixes the cost for resources in a more stable way.
Freeloading
The history of the Internet records a number of users who have freely donated resources. The hacker ethos and the free software movement can be relied on to provide resources to an extent. Johan Helsingius ran the initial "anonymous" remailer--anon.penet.fi--for its own sake. The Cypherpunks (Type I) and Mixmaster (Type II) remailers for anonymous email are run and maintained for free from around the globe. Processing for SETI@home and Distributed.net is also performed without compensation, other than the possibility of fame for finding an alien signature or cracking a key.
Unfortunately, not everybody donates equally. It is tempting for a user to "let somebody else pay for it" and just reap the rewards.
Peer-to-peer systems may combat this effect by incorporating coercive measures into their design or deployment, ensuring that users actually donate resources. This is not a trivial problem. Napster provides a good example: users need to connect to Napster only when actually searching for MP3 files; otherwise they can remain offline. Furthermore, users are not forced to publicly share files, although downloaded files are placed in a public directory by default.
A fairly recent analysis of Gnutella traffic showed a lot of freeloading. One well-known study[14] found that almost 70% of users share no files, and nearly 50% of all responses are returned by the top 1% of sharing hosts.
Free Haven tackles this problem by attempting to ensure that users donate resources in amounts proportional to the resources they use. The system relies on accountability via reputation, which we discuss later. Mojo Nation, on the other hand, pays users Mojo--the system's private digital currency--for donated resources. Mojo has no meaning outside the system yet, but it can be leveraged for other system resources.
Fungible payments for accountability
Fungible micropayments are not used solely, or even largely, for economic incentives. Instead, they act as an accountability measure. Peers can't freeload in the system, as they can earn wealth only by making their own resources available (or by purchasing resource tokens via some other means). This is a more natural and more effective way to protect a system from flooding than proofs of work. In order to tie up resources protected by fungible payments, an adversary needs to donate a proportional amount of resources. The attempted denial of service becomes self-defeating.
If payments can actually be redeemed for real-world currencies, they provide yet another defense against resource misuse. It may still be true that powerful organizations (as opposed to a script-kiddie downloading DoS scripts from http://rootshell.com) can afford to pay enough money to flood a system. But now the victim can purchase additional physical disk space or bandwidth with the money earned. Since the prices of these computer resources drop weekly, the cost of successfully attacking the system increases with time.
Business arrangements, not technology, link digital cash to real-world currencies. Transactions can be visualized as foreign currency exchanges, because users need to convert an amount of money to digital cash before spending it. The Mark Twain Bank "issued" DigiCash eCash in the U.S. in the mid-1990s, joined by other banks in Switzerland, Germany, Austria, Finland, Norway, Australia, and Japan.[15] eCash can as easily be used for private currencies lacking real-world counterparts; indeed, Mojo is based on eCash technology (although without, in default form, the blinding operations that provide anonymity). The digital cash schemes we describe, therefore, can be used for both private and real-world currencies.
Micropayment digital cash schemes
Ronald Rivest and Adi Shamir introduced two simple micropayment schemes, PayWord and MicroMint, in 1996.[16] PayWord is a credit-based scheme based on chains of paywords (hash values), while MicroMint represents coins by k-way hash function collisions. Both of these schemes follow the lightweight philosophy of micropayments: nickels and dimes don't matter. If a user loses a payment or is able to forge a few payments, we can ignore such trivialities. The security mechanisms in these schemes are not as strong nor expensive as the full macropayment digital cash schemes we will discuss later. At a rough estimate, hashing is about 100 times faster than RSA signature verification and about 10,000 times faster than RSA signature generation.
PayWord is designed for applications in which users engage in many repetitive micropayment transactions. Some examples are pay-per-use web sites and pay-per-minute online games or movies. PayWord relies on a broker (better known as a "bank" in many digital cash schemes), mainly for online verification, but seeks to minimize communication with the broker in order to make the system as efficient as possible.
It works like this. Alice establishes an account with a broker and is issued a digital certificate. When she communicates with vendor Bob for the first time each day, she computes and commits to a new payword chain w1, w2, ..., wn. This chain is created by choosing some random wn and moving backward to calculate each hash wi from the hash wi+1.
Alice starts her relationship with Bob by offering w0. With each micropayment she moves up the chain from w0 toward wn. Just knowing w0, vendor Bob can't compute any paywords and therefore can't make false claims to the broker. But Bob can easily verify the ith payment if he knows only wi-1. Bob reports to the broker only once at the end of the day, offering the last (highest-indexed) micropayment and the corresponding w0 received that day. The broker adjusts accounts accordingly.
As payword chains are both user- and vendor-specific, the vendor can immediately determine if the user attempts to double-spend a payword. Unfortunately, however, PayWord does not provide any transaction anonymity. As this is a credit-based system, the broker knows that Alice paid Bob.
MicroMint takes the different approach of providing less security, but doing so at a very low cost for unrelated, low-value payments. Earlier, we described k-bit collisions, in which Alice found a value that matched the lowest k bits in Bob's hash. MicroMint coins are represented instead by full collisions: all the bits of the hashes have to be identical. A k-way collision is a set of distinct inputs (x1, x2, ..., xk) that all map to the same digests. In other words, hash(x1) = hash(x2) = ... = hash(xk). These collisions are hard to find, as the hash functions are specifically designed to be collision-free![17]
The security in MicroMint rests in an economy of scale: minting individual coins is difficult, yet once some threshold of calculations has been performed, coins can be minted with accelerated ease. Therefore, the broker can mint coins cost-effectively, while small-scale forgers can produce coins only at a cost exceeding their value.
As in PayWord, the MicroMint broker knows both Alice, to whom the coins are issued, and vendor Bob. This system is therefore not anonymous, allowing the broker to catch Alice if she attempts to double-spend a coin.
PayWord and MicroMint are just two representative examples of micropayment schemes. Many others exist. The point to notice in both schemes is the extreme ease of verification and the small space requirements for each coin. Not only are these schemes fast, but they remain fast even in environments with severe resource constraints or at larger amounts of money.
Micropayment schemes such as these make it possible to extend peer-to-peer applications beyond the desktop and into embedded and mobile environments. Routers can use micropayments to retard denial of service attacks with minimal extra computation and then store the proceeds. Music players can act as mobile Napster or Gnutella servers, creating ad hoc local networks to exchange music stored in their memories (and possibly make money in the process). These possibilities are just beginning to be explored.
Making money off others' work
Proofs of work can be exchanged for other resources in a system, even without a systemwide digital cash scheme. The key is to make a POW scheme in which Bob can take a POW submitted by Alice and pass it on to Charlie without expending any significant calculation of his own.
This scheme was introduced by Markus Jakobsson and Ari Juels in 1999 as a bread pudding protocol.[18] Bread pudding is a dish that originated with the purpose of reusing stale bread. In a similar spirit, this protocol defines a POW that may be reused for a separate, useful, and verifiably correct computation. This computation is not restricted to any specific problem, although the authors further specify a simple bread pudding protocol for minting MicroMint coins.
In this variant on MicroMint's original minting scheme, the broker no longer has to generate each individual payment made by each user. Instead, a single, valid coin can be redistributed by users in the system to satisfy each others' POWs. The fundamental idea is to make clients solve partial hash collisions, similar to the concept of hash cash. This computation is useful only to the mint, which holds some necessary secret. With enough of these POWs, the minter can offload the majority of computations necessary to minting a coin.
Effectively, Bob is asking Alice to compute part of a MicroMint coin, but this partial coin is useful only when combined with thousands or millions of other similar computations. Bob collects all of these computations and combines them into MicroMint coins. Without requiring systemwide fungible digital cash, Bob can reuse others' computation work for computations of value to him (and only to him). The scheme is extensible and can potentially be used with many different types of payment schemes, not just MicroMint.
Anonymous macropayment digital cash schemes
Up until now, we have described payments in which the value of each coin or token is fairly small. These make forgery difficult because it's useful only if it can be performed on a large scale. Now we will move to more complex schemes that allow large sums to be paid in a secure manner in a single transaction. These schemes also offer multiparty security and some protection for user privacy.
The macropayment digital cash schemes we are about to discuss offer stronger security and anonymity. However, these protections come at a cost. The computational and size requirements of such digital cash are much greater. In cryptographic literature, micropayments are usually considered extremely small (such as $0.01) and use very efficient primitives such as hash functions. In contrast, macropayment digital cash schemes use public key operations, such as exponentiation, which are much slower. The use of techniques from elliptic curve cryptography can alleviate this problem by making it possible to securely use much shorter keys.
Other clever tricks, such as "probabilistic" checking--checking selected payments on the grounds that large-scale forgery will be caught eventually--can help macropayment techniques compete with micropayment schemes. This is an active research area and a source of continual innovation. Macropayment schemes will prove useful when used with the reputation systems discussed later in this chapter in the section "Reputations," because reputation systems let us make large transactions without assuming incommensurate risk.
Pioneering work on the theoretical foundations of anonymous digital cash was carried out by David Chaum in the early 1980s.[19] Chaum held patents on his electronic cash system, and founded DigiCash in 1990 to implement his ideas, but he exclusively licensed his patents to Ecash Technologies in 1999.
The electronic cash system he developed is based on an extension of digital signatures, called blind signatures. A digital signature uses a PKI to authenticate that a particular message was sent by a particular person. (See Chapter 15 for a greater description of signatures and PKI.) A blind signature scheme allows a person to get a message signed by another party, while not revealing the message contents to that party or allowing the party to recognize the message later.
In digital cash, Alice creates some number called a proto-coin and "blinds" it by multiplying by a secret random number. She sends this blinded proto-coin to the bank, which cannot link it with the original proto-coin. The bank checks that she has a positive balance and signs the proto-coin with the assurance that "this is a valid coin," using a private key specific to the particular amount of money in the coin. The bank returns this to Alice and subtracts the corresponding amount from Alice's bank account. Alice then divides out the random number multiplier and finds herself with a properly minted coin, carrying a valid signature from the bank. This is just one way to do digital cash, but it will suffice for this discussion.
In real life, the digital cash transaction would be like Alice slipping a piece of paper into a carbon-lined envelope, representing the blinded proto-coin. The bank just writes its signature across the envelope, which imprints a carbon signature onto the inside paper. Alice removes the paper and is left with a valid coin.
Alice can then spend this coin with Bob. Before accepting it, Bob needs to check with the issuing bank that the coin hasn't already been spent, a process of online verification. Afterwards, Bob can deposit the coin with the bank, which has no record of to whom that coin was issued. It saw only the blinded proto-coin, not the underlying "serial" number.
This digital cash system is both anonymous and untraceable. Its disadvantage, however, is that coins need to be verified online during the transaction to prevent double-spending. This slows down each transaction.
Stefan Brands proposed an alternative digital cash scheme in 1993.[20] It forms the core of a system implemented and tested by CAFE, a European project with both academic and commercial members. His patents are currently held by the Montreal-based privacy company Zero-Knowledge Systems, Inc.
Brands's digital cash scheme allows offline checking of double-spending for fraud tracing, with obvious performance benefits compared to online verification. It is also well suited for incorporation into smart cards, and the underlying technology provides an entire framework for privacy-protecting credential systems.
Brands's scheme uses a restrictive blind signature protocol rather than a normal blind signature protocol as proposed by Chaum. In the digital cash context, this certificate is a valid coin, represented as three values--secret key, public key, and digital signature--certified by the bank. A key aspect of this protocol is that the bank knows--and encodes attributes into--part of Alice's secret key, but it has no idea what the corresponding public key and certificate look like (except that they are consistent with the known part of the secret key). At the end of the issuing protocol, Alice uses techniques somewhat similar to Chaum's protocol to generate a valid coin.
Payment is very different in Brands's system. Alice's coin contains her secret key, so she doesn't actually give her coin to the vendor Bob. Instead, she proves to Bob that she is the proper holder of that coin (that is, that she knows the secret key associated with the public key), without actually disclosing its contents. This type of payment, a signed proof of knowledge transcript, is a fundamental shift from Chaum's e-cash model, in which the coin is merely an "immutable" bit string.
Privacy is maintained together with honesty by Brands's system in a very clever manner. If Alice only spends the coin once, the bank can gain no information as to her identity. After all, during the issuing protocol, the bank saw only part of Alice's secret key, not the public key used to verify Alice's payment transcript signature. Nor did the bank see its own signature on that public key. Yet if Alice double-spends the coin, the bank can use it to extract her identity!
We won't provide the math necessary to understand the security in this system, but you can understand why it works by comparing it to a Cartesian x-y plane. The first random number challenge used during payment provides one point (x0,y0) on this plane. An infinite number of lines can pass through this one point. If Alice uses the same coin to pay Charlie, a different random number is used. Now we know a second (x1,y1) point, and two points uniquely define a line. In the same way, Alice's identity will be exposed if she spends the coin twice.
Brands's scheme--useful for both digital cash and credentials--can be used to encode other useful information, such as negotiable attributes exposed during payment or high-value secrets that can prevent lending. A "high-value secret" refers to the same strategy we discussed when trying to prevent people from sharing their accounts--if a certificate to do X includes the user's credit card number, the user will be less willing to loan the certificate to others.
The "negotiable attributes" are an extension of a powerful idea--that of "credentials without identity." If you have a credential without identity, you have a way of proving that you belong to a certain class of people without actually having to prove anything about who you are. For example, you may have a credential which certifies that you are over 21 but doesn't include your name. The entity that authorized your age wouldn't want you to be able to lend this certificate to someone else. Therefore, we utilize these high-value secrets: the user needs to know the secret in order to use the over-21 certificate. Brands's scheme takes this farther and allows you to selectively reveal or hide various certifications on the fly, thereby allowing you to negotiate your degree of privacy.
One final note: whether a peer-to-peer system uses micropayments or macropayments, system designers must consider the possibility that these can be DoS targets in themselves. Perhaps an attacker can flood a system with cheaply minted counterfeit coins, eating up computational resources through verification-checking alone. The extent of this problem depends largely on the computational complexity of coin verification. Many of the systems we describe--hash cash, client puzzles, MicroMint, PayWord--can very quickly verify coins with only a single or a few hash operations. Public key operations, such as modular exponentiation, can be significantly more expensive. Again, digital cash schemes are an active area of cryptographic research; before specifying a scheme it is worth checking out the proceedings of the Financial Cryptography, CRYPTO, and EUROCRYPT conferences.
The use and effectiveness of micropayments in peer-to-peer systems
So far, we have spent quite a bit of time describing various micropayment and digital cash schemes. Our discussion is not meant as exhaustive, yet it provides some examples of various cryptographic primitives and technologies used for electronic cash: public key encryption, hash functions, digital signatures, certificates, blinding functions, proofs of knowledge, and different one-way and trap door problems based on complexity theory. The list reads like a cryptographic cookbook. Indeed, the theoretical foundations of digital cash--and the design of systems--have been actively researched and developed over the past two decades.
Only in the past few years, however, have we begun to see the real-world application of micropayments and digital cash, spurred by the growth of the Internet into a ubiquitous platform for connectivity, collaboration, and even commerce. Electronic cash surely has a place in future society. But its place is not yet secured. We are not going to try to predict either how fast or how widespread its adoption will be; that depends on too many economic, social, and institutional factors.
Instead, we'll focus on how micropayments might be useful for peer-to-peer systems: what issues the developers of peer-to-peer systems need to consider, when certain digital cash technologies are better than others, how to tell whether the micropayments are working, and how to achieve stronger or weaker protections as needed.
Identity-based payment policies
When designing a policy for accepting micropayments, a peer-to-peer system might wish to charge a varying amount to peers based on identity. For instance, a particular peer might charge less to local users, specified friends, users from academic or noncommercial subnets, or users within specified jurisdictional areas.
Such policies, of course, depend on being able to securely identify peers in the system. This can be hard to do both on the Internet as a whole (where domain names and IP addresses are routinely spoofed) and, in particular, on systems that allow anonymity or pseudonymity. Chapter 15 discusses this issue from several general angles, and Chapter 12 discusses how we try to solve the problem in one particular pseudonymous system, Free Haven. Many other systems, like ICQ and other instant messaging services, use their own naming schemes and ensure some security through passwords and central servers. Finally, systems with many far-flung peers need a reputation system to give some assurance that peers won't abuse their privileges.
General considerations in an economic analysis of micropayment design
Designers choosing a micropayment scheme for a peer-to-peer system should not consider merely the technical and implementation issues of different micropayment schemes, but also the overall economic impact of the entire system. Different micropayment schemes have different economic implications.
A classic economic analysis of bridge tolls serves as a good analogy for a peer-to-peer system. In 1842, the French engineer Jules Dupuit reached a major breakthrough in economic theory by arguing the following: the economically efficient toll on an uncongested bridge is zero, because the extra cost from one more person crossing the bridge is zero. Although bridge building and maintenance is not free--it costs some money to the owner--it is socially inefficient to extract this money through a toll. Society as a whole is worse off because some people choose not to cross due to this toll, even though their crossing would cost the owner nothing, and they would not interfere with anyone else's crossing (because the bridge is uncongested). Therefore, everyone should be allowed to cross the bridge for free, and the society should compensate the bridge builder through a lump-sum payment.[21]
This bridge example serves as a good analogy to a peer-to-peer system with micropayments. Tolls should be extracted only in order to limit congestion and to regulate access to people who value crossing the most. Given the same economic argument, resource allocation to limit congestion is the only justifiable reason for micropayments in a peer-to-peer system. Indeed, excessive micropayments can dissuade users from using the system, with negative consequences (known as "social inefficiencies") for the whole society. Users might not access certain content, engage in e-commerce, or anonymously publish information that exposes nefarious corporate behavior.
This analysis highlights the ability of micropayments to prevent attacks and adds the implied ability to manage congestion. Congestion management is a large research area in networking. Micropayments can play a useful role in peer-to-peer systems by helping peers prioritize their use of network bandwidth or access to storage space. Users who really want access will pay accordingly. Of course, such a system favors wealthy users, so it should be balanced against the goal of providing a system with the broadest social benefits. Reputation can also play a role in prioritizing resource allocation.
Most economic research relevant for micropayments has focused on owner-side strategies for maximizing profit. AT&T researchers compared flat-fee versus pay-per-use fee methods where the owner is a monopolist and concluded that more revenues are generated with a flat-fee model. Similar research at MIT and NYU independently concluded that content bundling and fixed fees can generate greater profits per good.[22]
We try to take a broader view. We have to consider the well-being of all economic agents participating in and affected by the system. Three general groups come to mind in the case of a peer-to-peer system: The owner of the system, the participants, and the rest of society.
How does a micropayment scheme impact these three agents? Participants face direct benefits and costs. The owner can collect fees or commissions to cover the fixed cost of designing the system and the variable costs of its operation. The rest of society can benefit indirectly by synergies made possible by the system, knowledge spillovers, alternative common resources that it frees up, and so on.
To simplify our discussion, we assume that whatever benefits participants also benefits society. Furthermore, we can realistically assume a competitive market, so that the owner is probably best off serving the participants as well as possible. Therefore, we focus on the cost/benefit analysis for the participant.
We believe that a focus on costs and benefits to participants is more suited to the peer-to-peer market than the literature on information services, for several reasons. First, peer-to-peer system owners do not enjoy the luxury of dictating exchange terms, thanks to competition. Second, nonfungible micropayments do not generate revenues for the owner; it is not always worthwhile to even consider the benefit to the owner. Third, we expect that a large amount of resources in peer-to-peer systems will be donated by users: people donate otherwise unused CPU cycles to SETI@home calculations, unused bandwidth to forward Mixmaster anonymous email, and unused storage for Free Haven data shares. For these situations, the sole role of micropayments is to achieve optimal resource allocation among participants. In other words, micropayments in a peer-to-peer system should be used only to prevent congestion, where this concept covers both bandwidth and storage limitations.
Moderating security levels: An accountability slider
Poor protection of resources can hinder the use of a peer-to-peer system on one side; attempts to guard resources by imposing prohibitive costs can harm it on the other. Providing a widely used, highly available, stable peer-to-peer system requires a balance.
If a peer-to-peer system wishes only to prevent query-flooding (bandwidth) attacks, the congestion management approach taken by client puzzles--and usable with any form of micropayment--answers the problem. Query-flooding attacks are transient; once the adversary stops actively attacking the system, the bandwidth is readily available to others.
As we have suggested, other forms of congestion are cumulative, such as those related to storage space. Free Haven seeks "document permanence," whereby peers promise to store data for a given time period (although the Free Haven trading protocol seeks to keep this system dynamic, as discussed in Chapter 12). If we wait until the system is already full before charging micropayments, we've already lost our chance to adequately protect against congestion.
This is the freeloading problem: we wish to prevent parasitic users from congesting the system without offering something of value in return. Furthermore, an adversary can attempt to flood the system early to fill up all available space. Therefore, for systems in which resource pressures accrue cumulatively, micropayments should always be required. Free Haven's answer is to require that peers offer storage space proportional to that which they take up. (Even though cash-based micropayments are not used, the idea of payment by equivalent resources is similar.)
The alternative to this design is the caching approach taken by systems such as Freenet. Old data is dropped as newer and more "popular" data arrives. This approach does not remove the resource allocation problem, however; it only changes the issue. First, flooding the system can flush desirable data from nearby caches as well. System designers simply try to ensure that flooding will not congest the resources of more distant peers. Second, freeloading is not as much of a concern, because peers are not responsible for offering best-effort availability to documents. However, if many peers rely on a few peers to store data, only the most popular data remains. Social inefficiencies develop if the system loses data that could be desired in the long run because short-term storage is insufficient to handle the requirements of freeloading peers. Furthermore, disk space is only one of several resources to consider. Massive freeloading can also affect scalability through network congestion.
Always charging for resources can prevent both freeloading and attacks. On the other hand, excessive charges are disadvantageous in their own right. So it would be useful to find a balance.
Consider an accountability slider: Peers negotiate how much payment is required for a resource within a general model specified by the overall peer-to-peer system. Using only a micropayment model, systems like Free Haven or Publius may not have much leeway. Others, like Freenet, Gnutella, or Jabber, have notably more. When we later add the concept of reputation, this accounting process becomes even more flexible.
Each of the micropayment schemes described earlier in this chapter can be adapted to provide a sliding scale:
- Hash cash
- Partial hashes can be made arbitrarily expensive to compute by choosing the desired number of bits of collision, denoted by k. No matter how big k gets, systems providing the resources can verify the requests almost instantly.
- Client puzzles
- The work factor of these puzzles is also based on the number of bit collisions. The number of subpuzzles can also be increased to limit the possibility of random guessing being successful; this is especially important when k becomes smaller.
- Time puzzles
- The LCS35 time-lock includes a parameter t that sets the difficulty of the puzzle.
- MicroMint
- The "cost" of a coin is determined by its number of colliding hash values. The greater the k-way collision, the harder the coin is to generate.
- PayWord
- In the simplest adaptation, a commitment within PayWord can be a promise of varying amount. However, PayWord is designed for iterative payments. To be able to use the same PayWord chain for successive transactions, we want to always pay with coins of the same value. Therefore, to handle variable costs, we can just send several paywords for one transaction. The very lightweight cost of creating and verifying paywords (a single hash per payword) also makes this multiple-coin approach suitable for macropayment schemes.
- Anonymous digital cash
- Coins can have different denominations. In Chaum's design, the bank uses a different public key to sign the coin for different denominations. In Brands's model, the denomination of the coin is encoded within the coin's attributes; the bank's public key is unique to currency, not denomination. Brands's digital cash system also allows negotiable attributes to be revealed or kept secret during payment. This additional information can play a role in setting the accountability slider.
By negotiating these various values, we can change the level of accountability and security offered by a peer-to-peer system. Based on overall system requirements, this process can be fixed by the system designers, changed by the administrators of individual peer machines, or even fluctuate between acceptable levels at runtime!
While payment schemes can be used in a variety of peer-to-peer situations--ranging from systems in which peers are fully identified to systems in which peers are fully anonymous--they do involve some risk. Whenever Alice makes an electronic payment, she accepts some risk that Bob will not fulfill his bargain. When identities are known, we can rely on existing legal or social mechanisms. In fully anonymous systems, no such guarantee is made, so Alice attempts to minimize her risk at any given time by making small, incremental micropayments. However, there is another possibility for pseudonymous systems, or identified systems for which legal mechanisms should only be used as a last resort: reputation schemes. In this next section, we consider the problem of reputation in greater depth.
Reputations
While micropayments provide an excellent mechanism for anonymous exchange, a number of systems call for more long-term pseudonymous or even public relationships. For instance, in the case of transactions in which one party promises a service over a long period of time (such as storing a document for three years), a simple one-time payment generally makes one party in the transaction vulnerable to being cheated. A whistleblower or political dissident who publishes a document may not wish to monitor the availability of this document and make a number of incremental micropayments over the course of several years, since this requires periodic network access and since continued micropayments might compromise anonymity. (While third-party escrow monitoring services or third-party document sponsors might help to solve this issue, they introduce their own problems.) In addition, some systems might want to base decisions on the observed behavior of entities--how well they actually perform--rather than simply how many resources they can provide.
In the real world, we make use of information about users to help distribute resources and avoid poor results. Back before the days of ubiquitous communication and fast travel, doing business over long distances was a major problem. Massive amounts of risk were involved in, say, sending a ship from Europe to Asia for trade. Reputations helped make this risk bearable; large banks could issue letters of credit that could draw on the bank's good name both in Europe and Asia, and they could insure expeditions against loss. As the bank successfully helped expeditions finance their voyages, the bank's reputation grew, and its power along with it. Today's business relationships still follow the same path: two parties make a decision to trust each other based on the reputations involved.
While the online world is different from the brick-and-mortar world, it too has benefited from reputations--and can continue to benefit.
The main difference between reputation-based trust systems and micropayment-based trust systems is that, in reputation-based trust systems, parties base their decisions in part on information provided by third parties. Peers are motivated to remain honest by fear that news of misdealings will reach yet other third parties.
Reputation systems are not useful in all situations. For instance, if there were thousands of buyers and one or two vendors, being able to track vendor performance and reliability would not help buyers pick a good vendor. On the other hand, tracking performance might provide feedback to the vendor itself on areas in which it might need improvement. This in turn could result in better performance down the road, but only if the vendor acted on this feedback.
Similarly, in fields in which a given buyer generally doesn't perform transactions frequently, the benefits of a reputation system are more subtle. A buyer might benefit from a real estate reputation system, since she expects to rent from different people over time. Even for a domain in which she expects to do just one transaction over her whole lifetime (such as laser eye surgery), she would probably contribute to a reputation site--first out of altruism, and second in order to give the surgeon an incentive to do well.
This is the tragedy of the commons in reverse: when the cost of contributing to a system is low enough, people will contribute to it for reasons not immediately beneficial to themselves.
Chapter 17, Reputation, describes some of the practical uses for a reputation system and the difficulties of developing such a system. That chapter focuses on the solution found at Reputation Technologies, Inc. In this chapter we'll give some background on reputation and issues to consider when developing a reputation system.
Early reputation systems online
The online world carries over many kinds of reputation from the real world. The name "Dennis Ritchie" is still recognizable, whether listed in a phone book or in a posting to comp.theory. Of course, there is a problem online--how can you be sure that the person posting to comp.theory is the Dennis Ritchie? And what happens when "Night Avenger" turns out to be Brian Kernighan posting under a pseudonym? These problems of identity--covered earlier in this chapter--complicate the ways we think about reputations, because some of our old assumptions no longer hold.
In addition, new ways of developing reputations evolve online. In the bulletin board systems of the 1980s and early 1990s, one of the more important pieces of data about a particular user was her upload/download ratio. Users with particularly low ratios were derided as "leeches," because they consumed scarce system resources (remember, when one user was on via a phone line, no one else could log in) without giving anything in return. As we will see, making use of this data in an automated fashion is a promising strategy for providing accountability in peer-to-peer systems.
Codifying reputation on a wide scale: The PGP web of trust
Human beings reason about reputations all the time. A large-scale peer-to-peer application, however, cannot depend on human judgments for more than a negligible portion of its decisions if it has any hope of scalability. Therefore, the next step in using reputations is to make their development and consequences automatic.
We've already mentioned the value of knowing upload/download ratios in bulletin board systems. In many systems, gathering this data was automatic. In some cases, the consequences were automatic as well: drop below a certain level and your downloading privileges would be restricted or cut off entirely. Unfortunately, these statistics did not carry over from one BBS to another--certainly not in any organized way--so they provided for reputations only on a microscopic scale.
One of the first applications to handle reputations in an automated fashion on a genuinely large scale was the "web of trust" system introduced in Phil Zimmermann's Pretty Good Privacy (PGP). This was the first program to bring public key cryptography to the masses. In public key cryptography, there are two keys per user. One is public and can be used only to encrypt messages. The other key is private and can be used only to decrypt messages. A user publishes his public key and keeps the private key safe. Then others can use the public key to send him messages that only he can read.
With public key cryptography comes the key certification problem, a type of reputation issue. Reputations are necessary because there is no way to tell from the key alone which public key belongs to which person.
For example, suppose Alice would like people to be able to send encrypted messages to her. She creates a key and posts it with the name "Alice." Unbeknownst to her, Carol has also made up a key with the name "Alice" and posted it in the same place. When Bob wants to send a message to Alice, which key does he choose? This happens in real life; as an extreme example, the name "Bill Gates" is currently associated with dozens of different PGP keys available from popular PGP key servers.
So the key certification problem in PGP (and other public key services) consists of verifying that a particular public key really does belong to the entity to whom it "should" belong. PGP uses a system called a web of trust to combat this problem. Alice's key may have one or more certifications that say "Such and such person believes that this key belongs to Alice." These certifications exist because Alice knows these people personally; they have established to their satisfaction that Alice really does own this key. Carol's fake "Alice" key has no such certifications, because it was made up on the spot.
When Bob looks at the key, his copy of PGP will assign it a trust level based on how many of the certifications are made by people he knows. The higher the trust level, the more confidence Bob can have in using the key.
A perennial question about the web of trust, however, is whether or not it scales. Small groups of people can create a web of trust easily, especially if they can meet each other in person. What happens when we try to make the web of trust work for, say, a consumer and a merchant who have never met before? The conventional wisdom is that the web of trust does not scale. After all, there is a limit to how many people Alice and Bob can know.
The most frequently cited alternative to the web of trust is a so-called Public Key Infrastructure. Some trusted root party issues certificates for keys in the system, some of which go to parties that can issue certificates in turn. The result is to create a certification tree. An example is the certificate system used for SSL web browsers; here VeriSign is one of the trusted root certificate authorities responsible for ensuring that every public key belongs to the "right" entity. A hierarchical system has its own problems (not least the fact that compromise of the root key, as may recently have happened to Sun Microsystems,[23] is catastrophic), but at least it scales, right?
As it turns out, the web of trust may not be as unworkable as conventional wisdom suggests. A study of publicly available PGP keys in 1997 showed that on average, only six certificates linked one key to another.[24] This "six degrees of separation" or "small-world" effect (also discussed in Chapter 14) means that for a merchant and a user who are both good web of trust citizens--meaning that they certify others' keys and are in turn certified--the odds are good that they will have reason to trust each others' keys. In current practice, however, most commercial sites elect to go with VeriSign. The one major commercial exception is Thawte's Freemail Web of Trust system.[25]
A more serious problem with PGP's implementation of the web of trust, however, comes with key revocation. How do you tell everyone that your key is no longer valid? How do you tell everyone that your certificate on a key should be changed? For that matter, what exactly did Bob mean when he certified Charlie's key, and does Charlie mean the same thing when he certifies David's key?
A more sophisticated--but still distributed--approach to trust management that tries to settle these questions is the Rivest and Lampson Simple Distributed Security Infrastructure/Simple Public Key Infrastructure (SDSI/SPKI). A thorough comparison of this with PGP's web of trust and PKI systems is given by Yang, Brown, and Newmarch.[26]
All of this brings up many issues of trust and public key semantics, about which we refer to Khare and Rifkin.[27] The point we're interested in here is the way in which the web of trust depends on reputation to extend trust to new parties.
Who will moderate the moderators: Slashdot
The news site Slashdot.org is a very popular news service that attracts a particular kind of "Slashdot reader"--lots of them. Each and every Slashdot reader is capable of posting comments on Slashdot news stories, and sometimes it seems like each and every one actually does. Reputations based on this interaction can help a user figure out which of the many comments are worth reading.
To help readers wade through the resulting mass of comments, Slashdot has a moderation system for postings. Certain users of the system are picked to become moderators. Moderators can assign scores to postings and posters. These scores are then aggregated and can be used to tweak a user's view of the posts depending on a user's preferences. For example, a user can request to see no posts rated lower than 2.
The Slashdot moderation system is one existing example of a partially automated reputation system. Ratings are entered by hand, using trusted human moderators, but then these ratings are collected, aggregated, and displayed in an automatic fashion.
Although moderation on Slashdot serves the needs of many of its readers, there are many complaints that a posting was rated too high or too low. It is probably the best that can be done without trying to maintain reputations for moderators themselves.
Reputations worth real money: eBay
The eBay feedback system is another example of a reputation service in practice. Because buyers and sellers on eBay usually have never met each other, neither has much reason to believe that the other will follow through on their part of the deal. They need to decide whether or not to trust each other.
To help them make the decision, eBay collects feedback about each eBay participant in the form of ratings and comments. After a trade, eBay users are encouraged to post feedback about the trade and rate their trading partner. Good trades, in which the buyer and seller promptly exchange money for item, yield good feedback for both parties. Bad trades, in which one party fails to come through, yield bad feedback which goes into the eBay record. All this feedback can be seen by someone considering a trade.
The idea is that such information will lead to more good trades and fewer bad trades--which translates directly into more and better business for eBay. As we will see, this isn't always the case in practice. It is the case often enough, however, to give eBay a reputation of its own as the preeminent web auction site.
A reputation system that resists pseudospoofing: Advogato
Another example of reputations at work is the "trust metric" implemented at http://www.advogato.org, which is a portal for open source development work. The reputation system is aimed at answering the fundamental question, "How much can you trust code from person X?" This question is critical for people working on open source projects, who may have limited time to audit contributed code. In addition, in an open source project, attempts by one contributor to fix the perceived "mistakes" of another contributor may lead to flame wars that destroy projects. As of this writing, the open source development site http://www.sourceforge.net (host to Freenet) is considering using a similar reputation system.
The stakes at Advogato are higher than they are at Slashdot. If the Slashdot moderation system fails, a user sees stupid posts or misses something important. If the Advogato trust metric incorrectly certifies a potential volunteer as competent when he or she is not, a software project may fail. At least, this would be the case if people depended on the trust metric to find and contact free software volunteers. In practice, Advogato's trust metric is used mostly for the same application as Slashdot's: screening out stupid posts.
The method of determining trust at Advogato also contains features that distinguish it from a simple rating system like Slashdot moderation. In particular, the Advogato trust metric resists a scenario in which many people join the system with the express purpose of boosting each others' reputation scores.[28]
Advogato considers trust relationships as a directed flow graph. That is, trust relationships are represented by a collection of nodes, edges, and weights. The system is illustrated in Figure 16-1 (we omit weights for simplicity). The nodes are the people involved. An edge exists between A and B if A trusts B. The weight is a measure of how much A trusts B.
|
|
What we are interested in, however, is not just how much A trusts B, but how much B is trusted in general. So Advogato measures how much trust "flows to" B, by designating a few special trusted accounts as a source and by designating B as a sink. It then defines a flow of trust from the source to B as a path from the source to B. Advogato assigns numbers to edges on the path that are less than or equal to the edge weights. The edge weights act as constraints on how much trust can be "pushed" between two points on the flow path. Finally, the trust value of B is defined as the maximum amount of trust that can be pushed from the source to B--the maximum flow.
Calculating flows through networks is a classic problem in computer science. Advogato uses this history in two ways. First, the Ford-Fulkerson algorithm lets the system easily find the maximum flow, so B's trust value can always be computed.[29] Second, a result called the "maxflow-mincut theorem" shows that the Advogato system resists the pseudospoofing attacks described earlier, in the section "Problems with pseudospoofing and possible defenses." Even if one entity joins under many different assumed names, none of these names will gain very much more trust than if each had joined alone.
Pseudospoofing is resisted because each of the new names, at least at first, is connected only to itself in the graph. No one else has any reason whatsoever to trust it. Therefore, there is no trust flow from the source to any of the pseudospoofing nodes, and none of them are trusted at all. Even after the pseudospoofing nodes begin to form connections with the rest of the graph, there will still be "trust bottlenecks" that limit the amount of trust arriving at any of the pseudospoofing nodes.
This property is actually quite remarkable. No matter how many fake names an adversary uses, it is unable to boost its trust rating very much. The downside is that nodes "close" to the source must be careful to trust wisely. In addition, it may not be readily apparent what kinds of weights constitute high trust without knowing what the entire graph looks like.
System successes and failures
Reputation in the brick-and-mortar world seems to work quite well; spectacular failures, such as the destruction of Barings Bank by the actions of a rogue trader, are exceptions rather than the rule. Which reputation-based systems have worked online, and how well have they worked?
The Slashdot and Advogato moderation systems seem to work. While it is difficult to quantify what "working" means, there have been no spectacular failures so far. On the other hand, the eBay fraud of mid-2000[30] shows some of the problems with reputation systems used naively.
In the eBay case, a group of people engaged in auctions and behaved well. As a result, their trust ratings went up. Once their trust ratings were sufficiently high to engage in high-value deals, the group suddenly "turned evil and cashed out." That is, they used their reputations to start auctions for high-priced items, received payment for those items, and then disappeared, leaving dozens of eBay users holding the bag.
As for PGP's web of trust, it has been overtaken by hierarchical PKIs, like those offered by VeriSign, as a widespread means of certifying public keys. In this case, peer-to-peer did not automatically translate into success.
Scoring systems
Reputation systems depend on scores to provide some meaning to the ratings as a whole. As shown in Chapter 17, scores can be very simple or involve multiple scales and complicated calculations.
In a reputation system for vendors, buyers might give ratings--that is, numbers that reflect their satisfaction with a given transaction--for a variety of different dimensions for each vendor. For instance, a given vendor might have good performance in terms of response time or customer service, but the vendor's geographic location might be inconvenient. Buyers provide feedback on a number of these rating dimensions at once, to provide a comprehensive view of the entity. The job of the reputation system is to aggregate these ratings into one or more published scores that are meaningful and useful to participants in the system. A good scoring system will possess many of the following qualities:
- Accurate for long-term performance
- The system reflects the confidence (the likelihood of accuracy) of a given score. It can also distinguish between a new entity of unknown quality and an entity with bad long-term performance.
- Weighted toward current behavior
- The system recognizes and reflects recent trends in entity performance. For instance, an entity that has behaved well for a long time but suddenly goes downhill is quickly recognized and no longer trusted.
- Efficient
- It is convenient if the system can recalculate a score quickly. Calculations that can be performed incrementally are important.
- Robust against attacks
- The system should resist attempts of any entity or entities to influence scores other than by being more honest or having higher quality.
- Amenable to statistical evaluation
- It should be easy to find outliers and other factors that can make the system rate scores differently.
- Private
- No one should be able to learn how a given rater rated an entity except the rater himself.
- Smooth
- Adding any single rating or small number of ratings doesn't jar the score much.
- Understandable
- It should be easy to explain to people who use these scores what they mean--not only so they know how the system works, but so they can evaluate for themselves what each score implies.
- Verifiable
- A score under dispute can be supported with data.
Note that a number of these requirements seem to be contradictory. We will explore the benefits and trade-offs from each of them over the course of the rest of this section.
Attacks and adversaries
Two questions determine how we evaluate the security of reputation systems. First, what information needs to be protected? Second, who are the adversaries?
The capabilities of potential adversaries and the extent to which they can damage or influence the system dictate how much energy should be spent on security. For instance, in the case of Free Haven, if political dissidents actually began using the system to publish their reports and information, government intelligence organizations might be sufficiently motivated to spend millions of dollars to track the documents to their sources.
Similarly, if a corporation planning a $50 million transaction bases its decisions on a reputation score that Reputation Technologies, Inc., provides, it could be worth many millions of dollars to influence the system so that a particular company is chosen. Indeed, there are quite a few potential adversaries in the case of Reputation Technologies, Inc. A dishonest vendor might want to forge or use bribes to create good feedback to raise his resulting reputation. In addition to wanting good reputations, vendors might like their competitors' reputations to appear low. Exchanges--online marketplaces that try to bring together vendors to make transactions more convenient--would like their vendors' reputations to appear higher than those of vendors that do business on other exchanges. Vendors with low reputations--or those with an interest in people being kept in the dark--would like reputations to appear unusably random. Dishonest users might like the reputations of the vendors that they use to be inaccurate, so that their competitors will have inaccurate information.
Perhaps the simplest attack that can be made against a scoring system is called shilling. This term is often used to refer to submitting fake bids in an auction, but it can be considered in a broader context of submitting fake or misleading ratings. In particular, a person might submit positive ratings for one of her friends (positive shilling) or negative ratings for her competition (negative shilling). Either of these ideas introduces more subtle attacks, such as negatively rating a friend or positively rating a competitor to try to trick others into believing that competitors are trying to cheat.
Shilling is a very straightforward attack, but many systems are vulnerable to it. A very simple example is the AOL Instant Messenger system. You can click to claim that a given user is abusing the system. Since there is no support for detecting multiple comments from the same person, a series of repeated negative votes will exceed the threshold required to kick the user off the system for bad behavior, effectively denying him service. Even in a more sophisticated system that detects multiple comments by the same person, an attacker could mount the same attack by assuming a multitude of identities.
Vulnerabilities from overly simple scoring systems are not limited to "toy" systems like Instant Messenger. Indeed, eBay suffers from a similar problem. In eBay, the reputation score for an individual is a linear combination of good and bad ratings, one for each transaction. Thus, a vendor who has performed dozens of transactions and cheats on only 1 out of every 4 customers will have a steadily rising reputation, whereas a vendor who is completely honest but has only done 10 transactions will be displayed as less reputable. As we have seen, a vendor could make a good profit (and build a strong reputation!) by being honest for several small transactions and then being dishonest for a single large transaction.
Weighting ratings by size of transaction helps the issue but does not solve it. In this case, large transactions would have a large impact on the reputation score of a vendor, and small transactions would have only a small impact. Since small transactions don't have much weight, vendors have no real incentive to be honest for them--making the reputation services useless for small buyers. Breaking reputation into many different dimensions, each representing the behavior of the vendor on a given category of transaction (based on cost, volume, region, etc.), can solve a lot of these problems. See the section "Scoring algorithms", later in this chapter for more details and an analysis of this idea.
Aspects of a scoring system
The particular scoring system or algorithm used in a given domain should be based on the amount of information available, the extent to which information must be kept private, and the amount of accuracy required.
In some situations, such as verifying voting age, a fine-grained reputation measurement is not necessary--simply indicating who seems to be sufficient or insufficient is good enough.
In a lot of domains, it is very difficult to collect enough information to provide a comprehensive view of each entity's behavior. It might be difficult to collect information about entities because the volume of transactions is very low, as we see today in large online business markets.
But there's a deeper issue than just whether there are transactions, or whether these transactions are trackable. More generally: does there exist some sort of proof (a receipt or other evidence) that the rater and ratee have actually interacted?
Being able to prove the existence of transactions reduces problems on a wide variety of fronts. For instance, it makes it more difficult to forge large numbers of entities or transactions. Such verification would reduce the potential we described in the previous section for attacks on AOL Instant Messenger. Similarly, eBay users currently are able to directly purchase a high reputation by giving eBay a cut of a dozen false transactions which they claim to have performed with their friends. With transaction verification, they would be required to go through the extra step of actually shipping goods back and forth.
Proof of transaction provides the basis for Amazon.com's simple referral system, "Customers who bought this book also bought..." It is hard to imagine that someone would spend money on a book just to affect this system. It happens, however. For instance, a publishing company was able to identify the several dozen bookstores across America that are used as sample points for the New York Times bestseller list; they purchased thousands of copies of their author's book at these bookstores, skyrocketing the score of that book in the charts.[31]
In some domains, it is to most raters' perceived advantage that everyone agree with the rater. This is how chain letters, Amway, and Ponzi schemes get their shills: they establish a system in which customers are motivated to recruit other customers. Similarly, if a vendor offered to discount past purchases if enough future customers buy the same product, it would be hard to get honest ratings for that vendor. This applies to all kinds of investments; once you own an investment, it is not in your interest to rate it negatively so long as it holds any value at all.
Collecting ratings
One of the first problems in developing reputation systems is how to collect ratings. The answer depends highly on the domain, of course, but there are a number of aspects that are common across many domains.
The first option is simply to observe as much activity as possible and draw conclusions based on this activity. This can be a very effective technique for automated reputation systems that have a lot of data available. If you can observe the transaction flow and notice that a particular vendor has very few repeat customers, he probably has a low reputation. On the other hand, lack of repeat customers may simply indicate a market in which any given buyer transacts infrequently. Similarly, finding a vendor with many repeat customers might indicate superior quality, or it might just indicate a market in which one or a few vendors hold a monopoly over a product. Knowledge of the domain in question is crucial to knowing how to correctly interpret data.
In many circumstances it may be difficult or impossible to observe the transaction flow, or it may be unreasonable to expect parties to take the initiative in providing feedback. In these cases, a reasonable option is to solicit feedback from parties involved in each transaction. This can be done either by publicizing interest in such feedback and providing incentives to respond, or even by actively going to each party after an observed transaction and requesting comments. Reputation Technologies, Inc., for instance, aggressively tries to obtain feedback after each transaction.
Tying feedback to transactions is a very powerful way of reducing vulnerabilities in the system. It's much more difficult for people to spam positive feedback, since each item of feedback has to be associated with a particular transaction, and presumably only the latest piece of feedback on a given transaction would actually count.
On the surface, it looks like this requires an exchange or other third-party transaction moderator, to make it difficult to simply fabricate a series of several thousand transactions and exploit the same vulnerability. However, vendors could provide blinded receipts for transactions--that is, the vendors would not be able to identify which buyer was providing the ratings. Without such a receipt, the reputation system would ignore feedback from a given buyer. Thus, buyers could not provide feedback about a vendor without that vendor's permission. There are a number of new problems introduced by this idea, such as how to respond if vendors fail to provide a receipt, but it seems to address many of the difficult issues about shilling in a decentralized environment.
A final issue to consider when collecting ratings is how fair the ratings will be--that is, how evenly distributed are the raters out of the set of people who have been doing transactions? If the only people who have incentive to provide ratings are those that are particularly unhappy with their transaction, or if only people with sufficient technical background can navigate the rating submission process, the resulting scores may be skewed to the point of being unusable. One solution to this could involve incentives that lead more people to respond; another approach is to simply collect so much data that the issue is no longer relevant. (The Slashdot moderation system, for instance, depends on the participation of huge numbers of independent moderators.) But systematic errors or biases in the ratings will generally defeat this second approach.
Bootstrapping
One of the tough questions for a reputation-based trust system is how to get started. If users make choices based on the scores that are available to them, but the system has not yet collected enough data to provide useful scores, what incentive do buyers have to use the system? More importantly, what incentive do they have to contribute ratings to the system?
Free Haven can avoid this problem through social means. Some participants will be generous and willing to try out new nodes just to test their stability and robustness. In effect, they will be performing a public service by risking some of their reputation and resources evaluating unknown nodes. However, businesses, particularly businesses just getting started in their fields and trying to make a name for themselves, won't necessarily be as eager to spend any of their already limited transaction volume on trying out unknown suppliers.
The way to present initial scores for entities depends on the domain. In some noncommercial domains, it might be perfectly fine to present a series of entities and declare no knowledge or preference; in others, it might be more reasonable to list only those entities for which a relatively certain score is known. Reputation Technologies needs to provide some initial value to the users; this can be done by asking vendors to provide references (that is, by obtaining out-of-band information) and then asking those references to fill out a survey describing overall performance of and happiness with that vendor. While this bootstrapping information may not be as useful as actual transaction-based feedback (and is more suspect because the vendors are choosing the references), it is a good starting point for a new system.
Bootstrapping is a much more pronounced issue in a centralized system than in a decentralized system. This is because in a decentralized system, each user develops his own picture of the universe: he builds his trust of each entity based on his own evidence of past performance and on referrals from other trusted parties. Thus, every new user effectively joins the system "at the beginning," and the process of building a profile for new users is an ongoing process throughout the entire lifetime of the system. In a centralized environment, on the other hand, ratings are accumulated across many different transactions and over long periods of time. New users trust the centralized repository to provide information about times and transactions that happened before the user joined the system.
In a newly developed system, or for a new entity in the system, the choice of the default reputation score is critical. If it's easy to create a new identity (that is, pseudonym), and new users start out with an average reputation, users who develop a bad reputation are encouraged to simply drop their old identities and start over with new ones. One way to deal with this problem is to start all new users with the lowest possible reputation score; even users with a bad track record will then have an incentive to keep their current identities.
Another approach to solving this problem is to make it difficult to create a new identity. For instance, this can be done by requiring some proof of identity or a monetary fee for registration. Tying the user to her real-world identity is the simplest, and probably the most effective, way to reduce abuse--but only if it's appropriate for that system.
Personalizing reputation searches
The user interface--that is, the way of presenting scores and asking questions--is a crucial element of a reputation system. Scores cannot simply be static universal values representing the overall quality of an individual. Since a score is an attempt to predict future performance, each score must be a prediction for a particular context. That is, the user interface must allow participants to query the system for the likelihood of a successful transaction for their particular situation. The more flexibility a client has, the more powerful and useful the system is (so long as users can still understand how to use it).
The user interface must also display a confidence value for each score--that is, how likely the score is to reflect the reality of the subject's behavior. The mechanism for generating this confidence value depends on the domain and the scoring algorithm. For instance, it might reflect the number of ratings used to generate the score, the standard deviation of the set of ratings, or the level of agreement between several different scoring algorithms that were all run against the ratings set. Confidence ratings are a major topic in Chapter 17.
Not only does a confidence value allow users to have a better feel for how firm a given score is, but it can also allow a more customized search. That is, a user might request that only scores with a certain minimum confidence value be displayed, which would weed out new users as well as users with unusual (widely varying) transaction patterns.
In some domains, qualitative statements (like verbal reviews) can enhance the value of a quantitative score. Simply providing a number may not feel as genuine or useful to users--indeed, allowing for qualitative statements can provide more flexibility in the system, because users providing feedback might discuss topics and dimensions which are difficult for survey authors to anticipate. On the other hand, it is very difficult to integrate these statements into numerical scores, particularly if they cover unanticipated dimensions. Also, as the number of statements increases, it becomes less useful to display all of them. Choosing which statements to display not only requires manual intervention and choice, but might also lead to legal liabilities. Another problem with providing verbal statements as part of the score is the issue of using this scoring system in different countries. Statements may need to be translated, but numbers are universal.
Scoring algorithms
As we've seen in the previous sections, there are many different aspects to scoring systems. While we believe that query flexibility is perhaps the most crucial aspect to the system, another important aspect is the actual algorithm used to aggregrate ratings into scores. Such an algorithm needs to answer most of the requirements that we laid out in the section "Scoring systems." Broadly speaking, the scoring algorithm should provide accurate scores, while keeping dishonest users from affecting the system and also preventing privacy leaks (as detailed in the next section).
Keeping dishonest users from affecting the system can be done in several ways. One simple way is to run statistical tests independent of the actual aggregation algorithm, to attempt to detect outliers or other suspicious behavior such as a clique of conspiring users. Once this suspicious behavior has been identified, system operators can go back, manually examine the system, and try to prune the bad ratings. While this appears to be a very time-intensive approach that could not possibly be used in a deployed system, eBay has used exactly this method to try to clean up their system once dishonest users have been noticed.[32]
A more technically sound approach is to weight the ratings by the credibility of each rater. That is, certain people contribute more to the score of a given entity based on their past predictive ability. Google makes use of this idea in its Internet search engine algorithm. Its algorithm counts the number of references to a given page; the more pages that reference that page, the more popular it is. In addition, the pages that are referenced from popular pages are also given a lot of weight. This simple credibility metric produces much more accurate responses for web searches.
By introducing the notion of local credibility rather than simple global credibility for each entity, the system can provide a great deal of flexibility and thus stronger predictive value. Local credibility means that a rating is weighted more strongly if the situation in which that rating was given is similar to the current situation. For instance, a small farmer in Idaho looking into the reputation of chicken vendors cares more about the opinion of a small farmer in Arkansas than he does about the opinion of the Great Chinese Farming Association. Thus, the algorithm would generate a score that more accurately reflects the quality of the vendor according to other similar buyers. Similarly, if Google knew more about the person doing the web search, it could provide an even more accurate answer. Before being bought by Microsoft, firefly.net offered a service based on this idea.
One of the problems with incorporating credibility into the scoring algorithm is that, in some domains, an individual's ability to perform the protocol honestly is very separate from an individual's ability to predict performance of others.
In the Free Haven system, for instance, a server may be willing to store documents and supply them to readers, but keep no logs about transactions or trades (so it has no idea which other servers are behaving honestly). In the case of Reputation Technologies, one vendor might be excellent at providing high-quality products on time, leading to a high reputation score, but possess only average skill at assessing other vendors. Indeed, a consulting firm might specialize in predicting performance of vendors but not actually sell any products of its own.
One way to solve this problem is to have separate scores for performance and credibility. This makes it more complex to keep track of entities and their reputations, but it could provide tremendous increases in accuracy and flexibility for scoring systems.
Weighting by credibility is not the only way to improve the accuracy and robustness of the scoring algorithm. Another approach is to assert that previous transactions should carry more weight in relation to how similar they are to the current transaction. Thus, a vendor's ability to sell high-quality Granny Smith apples should have some bearing on his ability to sell high-quality Red Delicious apples. Of course, this could backfire if the vendor in question specializes only in Granny Smith apples and doesn't even sell Red Delicious apples. But in general, weighting by the so-called category of the transaction (and thus the vendor's reputation in related categories) is a very powerful idea. Separating reputations into categories can act as a defense against some of the subtle shilling attacks described above, such as when a vendor develops a good reputation at selling yo-yos and has a side business fraudulently selling used cars.
The category idea raises very difficult questions. How do we pick categories? How do we know which categories are related to which other categories, and how related they are? Can this be automated somehow, or do the correlation coefficients have to be estimated manually?
In the case of Free Haven, where there is only one real commodity--a document--and servers either behave or they don't, it might be feasible to develop a set of categories manually and allow each server to manually configure the numbers that specify how closely related the categories are. For instance, one category might be files of less than 100K that expire within a month. A strongly related category would be files between 100K and 200K that expire within a month; perhaps we would say that this category is 0.9-related to the first. A mostly unrelated category would be files more than 500MB in size that expire in 24 months. We might declare that this category is 0.05-related to the first two.
With some experience, an algorithm might be developed to tweak the correlation coefficients on the fly, based on how effective the current values have been at predicting the results of future transactions. Similarly, we might be able to reduce the discrete categories into a single continuous function that converts "distance" between file size and expiration date into a correlation coefficient.
Reputation Technologies is not so lucky. Within a given exchange, buyers and sellers might barter thousands of different types of goods, each with different qualities and prices; the correlation between any pair of categories might be entirely unclear. To make matters worse, each vendor might only have a few transactions on record, leaving data too sparse for any meaningful comparison.
While we've presented some techniques to provide more accuracy and flexibility in using ratings, we still haven't discussed actual algorithms that can be used to determine scores. The simplest such algorithm involves treating reputations as probabilities. Effectively, a reputation is an estimate of how likely a future transaction in that category is to be honest. In this case, scores are simply computed as the weighted sum of the ratings.
More complex systems can be built out of neural networks or data-clustering techniques, to try to come up with ways of applying nonlinear fitting and optimizing systems to the field of reputation. But as the complexity of the scoring algorithm increases, it becomes more and more difficult for actual users of these systems to understand the implications of a given score or understand what flaws might be present in the system.
Finally, we should mention the adversarial approach to scoring systems. That is, in many statistical or academic approaches, the goal is simply to combine the ratings into as accurate a score as possible. In the statistical analysis, no regard is given for whether participants in the system can conspire to provide ratings that break the particular algorithm used.
A concrete example might help to illustrate the gravity of this point. One of the often referenced pitfalls of applying neural networks to certain situations comes from the U.S. military. They wanted to teach their computers how to identify tanks in the battlefield. Thus they took a series of pictures that included tanks, and a series of pictures that did not include tanks. But it turns out that one of the sets was taken during the night, and the other set was taken during the day. This caused their high-tech neural network to learn not how to identify a tank but how to distinguish day from night. Artificial intelligence developers need to remember that there are a number of factors that might be different in a set of samples, and their neural network might not learn quite what they want it to learn.
But consider the situation from our perspective: what if the Russian military were in charge of providing the tank pictures? Is there a system that can be set up to resist bad data samples? Many would consider that learning how to identify a tank under those circumstances is impossible. How about if the Russians could provide only half of the pictures? Only a tenth? Clearly this is a much more complicated problem. When developing scoring systems, we need to keep in mind that simply applying evaluation techniques that are intended to be used in a "clean" environment may introduce serious vulnerabilities.
Privacy and information leaks
Yet another issue to consider when designing a good scoring system is whether the system will be vulnerable to attacks that attempt to learn about the tendencies or patterns of entities in the system. In a business-oriented domain, knowledge about transaction frequency, transaction volume, or even the existence of a particular transaction might be worth a lot of time and money to competitors. The use of a simple and accurate scoring algorithm implies that it should be easy to understand the implication of a vendor's score changing from 8.0 to 9.0 over the course of a day. Perhaps one or more ratings arrived regarding large transactions, and those ratings were very positive.
The objectives of providing timeliness and accuracy in the scoring algorithm and of maintaining privacy of transaction data seem to be at odds. Fortunately, there are a number of ways to help alleviate the leakage problems without affecting accuracy too significantly. We will describe some of the more straightforward of these techniques in this section.
The problem of hiding transaction data for individual transactions is very similar to the problem of hiding source and destination data for messages going through mix networks.[33] More specifically, figuring out what kind of rating influenced a published score by a certain amount is very similar to tracking a message across a middleman node in a mix network. In both cases, privacy becomes significantly easier as transaction volume increases. Also in both cases, adversaries observe external aspects of the system (in the case of the scoring system, the change in the score; in the case of the mix network, the messages on the links to and from the mix node) to try to determine the details of some particular message or group of messages (or the existence of any message at all).
One common attack against the privacy of a scoring system is a timing attack. For instance, the adversary might observe transactions and changes in the scores and then try to determine the rating values that certain individuals submitted. Alternatively, the adversary might observe changes in the scores and attempt to discover information about the timing or size of transactions. These attacks are like watching the timings of messages going through various nodes on a mix network, and trying to determine which incoming message corresponds to which outgoing message.
A number of solutions exist to protect privacy. First of all, introducing extra latency between the time that ratings are submitted and the time when the new score is published can make timing correlation more difficult. (On the other hand, this might reduce the quality of the system, because scores are not updated immediately.) Another good solution is to queue ratings and process them in bulk. This prevents the adversary from being able to determine which of the ratings in that bulk update had which effect on the score.
A variant of this approach is the pooling approach, in which some number of ratings are kept in a pool. When a new rating arrives, it is added to the pool and a rating from the pool is chosen at random and aggregated into the score. Obviously, in both cases, a higher transaction volume makes it easier to provide timely score updates.
An active adversary can respond to bulk or pooled updates with what is known as an identification flooding attack. He submits ratings with known effect, and watches for changes in the score that are not due to those ratings. This approach works because he can "flush" the few anonymous ratings that remain by submitting enough known ratings to fill the queue. This attack requires the adversary to produce a significant fraction of the ratings during a given time period.
But all this concern over privacy may not be relevant at all. In some domains, such as Free Haven, the entire goal of the reputation system is to provide as much information about each pseudonymous server as possible. For instance, being able to figure out how Alice performed with Bob's transaction is always considered to be a good thing. In addition, even if privacy is a concern, the requirement of providing accurate, timely scores may be so important that no steps should be taken to increase user privacy.
Decentralizing the scoring system
Many of the issues we've presented apply to both centralized and decentralized reputation systems. In a decentralized system such as Free Haven, each server runs the entire reputation-gathering system independently. This requires each node to make do with only the information that it has gathered firsthand, and it generally requires a broadcast mechanism in order for all nodes to keep their information databases synchronized.
Another approach is to decentralize the scoring system itself, spreading it among the entire set of machines participating in the system. In this section, we present two ways of decentralizing a scoring system. The first exploits redundancy along with user flexibility to reduce the risk from cheating or compromised servers. The second is a more traditional approach to decentralizing a system, but it also brings along the more traditional problems associated with decentralization, such as high bandwidth requirements and difficult crypto problems.
Multiple trusted parties
Assume there is a set of scorers around the world, each independently run and operated. When a transaction happens, the vendor chooses a subset of the scorers and constructs a set of tickets. Each ticket is a receipt allowing the buyer to rate the vendor at a particular scorer. The receipts are blinded so that the vendor is not able to link a ticket with any given buyer.
At this point, the buyer can decide to which scorer or scorers he wishes to submit his ratings. Since each scorer could potentially use its own algorithm and have its own prices or publishing habits, each scorer might have its own set of trade-offs based on accuracy, privacy, and security. This technique allows the vendor to veto some of the scorers first. Then the rater chooses from among the remaining scorers. Thus, the ratings will only be submitted to mutually agreeable scorers.
We could extend this scenario to allow both parties in the transaction to provide tickets to each other, creating a more symmetric rating process. This approach introduces complications, because both parties in the transaction need to coordinate and agree on which tickets will be provided before the transaction is completed. There also needs to be some mechanism to enforce or publicize if one side of the transaction fails to provide the promised receipts.
The beauty of decentralizing the scoring system in this manner is that every individual in the system can choose which parts of the system they want to interact with. Participants in transactions can list scorers whom they trust to provide accurate scores, raters can choose scorers whom they trust not to leak rating information, and users looking for scores on various entities can choose scorers whom they trust to provide accurate scores.
Of course, this decentralization process introduces the issue of meta-reputation: how do we determine the reputations of the reputation servers? This sort of reputation issue is not new. Some Mixmaster nodes are more reliable than others,[34] and users and operators keep uptime and performance lists of various nodes as a public service. We expect that reputation scoring services would similarly gain (external) reputations based on their reliability or speed.
True decentralization
In this scenario, both sides of the transaction obtain blinded receipts as above. Apart from these raters, the system also consists of a set of collectors and a set of scorers. They are illustrated in Figure 16-2.
|
|
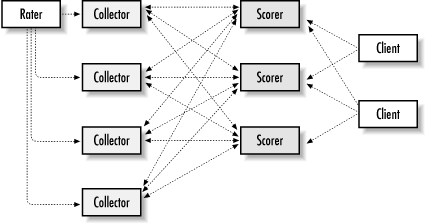
After the transaction, each rater splits up his rating using Shamir's secret sharing algorithm (described in Chapter 11, Publius) or some other k-of-n system. At this point, the rater submits one share of her rating to each collector. This means that the collectors together could combine the shares to determine her rating, but separately they can learn no information. It is the job of the scorers to provide useful information to clients: when a client does a reputation query for a specific category (situation), the scorer does the equivalent of an encrypted database query on the set of collectors.[35]
A number of technical challenges need to be solved in order to make this scheme work. First of all, the collectors need to have some mechanism for authenticating a rating without reading it. Similarly, they need to have some way to authorize a rater to put his share onto the system without their knowing the author of a given rating. Without this protection, malicious raters could simply flood the system with data until it overflowed.
Once these problems are solved, we need to come up with some sort of computationally feasible and bandwidth-feasible way of communication between the scorers and the collectors. We also need a set of rules that allow the scorers to get the information they need to answer a given query without allowing them to get too much information and learn more than they ought to learn about raters.
With this decentralization comes some subtle questions. Can scorers "accidentally forget" to include a specific rating when they're computing a score? Said another way, is there some way of allowing scorers to provide proof that they included a certain rating in the calculation of the score, without publishing the actual ratings that were used? This question is similar to the question of allowing mix nodes to prove that they forwarded a given message without yielding information that might help an adversary determine the source or destination of the message.[36]
A case study: Accountability in Free Haven
As described in Chapter 12, the Free Haven project is working toward creating a decentralized and dynamically changing storage service that simultaneously protects the anonymity of publishers, readers, and servers, while ensuring the availability of each document for a lifetime specified by the publisher. Our goals of strong anonymity and long-term persistent storage are at odds with each other. Providing as much anonymity as possible while still retaining sufficient accountability is a very difficult problem. Here we will describe the accountability requirements in greater detail than in Chapter 12 and discuss some approaches to solving them.
Our job is two-fold: We want to keep people from overfilling the bandwidth available from and between servers, and we want to keep people from overfilling the system with data. We will examine each of these goals separately.
Micropayments
In general, there are a number of overall problems with using micropayments in peer-to-peer systems. This general analysis will help motivate our discussion of using micropayments in the Free Haven context. We'll talk about them, then try to apply them to Free Haven.
The difficulty of distributed systems: How to exchange micropayments among peers
Consider the simple approach to micropayments introduced early in this chapter, in the section "Micropayment schemes." Alice wants resources operated by Bob. Alice pays Bob with some micropayments. Bob provides Alice with the access she purchased to his resources.
This sounds like a great model for economically-based distribution that provides both accountability and effective congestion-management of resources. However, the problem is rarely so simple in the case of peer-to-peer distributed systems on the Internet. The reason is that many intermediaries may be involved in a transaction--and one doesn't know who they are before the transaction starts, or perhaps even after the transaction is finished.
Consider an anonymous remailer like Mixmaster. Alice sends an email to Bob through a number of intermediate proxy remailers, which strip all identifying information from the message before transmitting it. This design is used to distribute trust across operational and often jurisdictional lines. Only a very powerful adversary--able to observe large sections of the network and use advanced traffic analysis techniques--should be able to link the sender and recipient of any given message. Hence, we achieve an essentially anonymous communications path for email.
Consider again the Gnutella routing protocol. Alice seeks some piece of information contained in the network. She sends out a query to all peers that she knows about (her "friends"); these peers in turn propagate the request along, branching it through the network. Hopefully, before the time-to-live (TTL) of the query expires, the request traverses enough intermediate hops to find Bob, who responds with the desired information. The Freenet routing protocol works similarly, covering some fraction of the surrounding network over the course of the search.
These examples highlight a design quite common in peer-to-peer systems, especially for systems focusing on anonymity (by distributing trust) or searching (by distributing content). That is, endpoint peers are not the only ones involved in an operation; Alice and Bob are joined by any number of intermediate peers. So how should we handle micropayments? What are the entities involved in a transaction? Four possible strategies are illustrated in Figure 16-3:
|
|
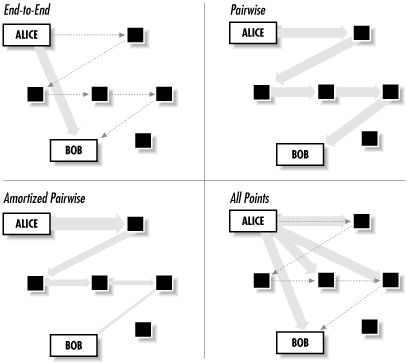
- End-to-end model
- The simplest approach is to make Alice send Bob some form of payment and not worry about what happens to any intermediaries. This model works fine for operations that do not make use of intermediate nodes. But if intermediate peers are involved, they lack any protection from attack. Bob might even be fictitious. Alice can attack any number of intermediate peers by routing her queries through them, using up their bandwidth or wiping out the data in Freenet-style data caches. This problem is precisely our motivation for using micropayments!
- Pairwise model
- Recognizing the problems of the end-to-end model, we can take a step upward in complexity and blindly throw micropayments into every transaction between every pair of peers. One long route can be modeled as a number of pairwise transactions. This model might appear to protect each recipient of payments, but it is also fundamentally flawed.
- Using fungible micropayments, each peer earns one unit from its predecessor and then spends one unit on its successor. Assuming equal costs throughout the network, Alice is the only net debtor and Bob the only net creditor. But if a single malicious operator is in charge of both Alice and Bob, these two peers have managed to extract work from the intermediate nodes without paying--a more subtle DoS or flooding attack!
- Using nonfungible micropayments, Alice remains a net debtor, but so are all intermediate peers. Alice can make use of greater computational resources (centralized or distributed) to flood intermediate peers with POWs. Being properly-behaving nodes, these peers attempt to make good on the micropayment exchange, and start churning out POWs for the next hop in the protocol... and churning... and churning. Eventually Alice can exhaust the resources of a whole set of smaller, honest peers.
- Amortized pairwise model
- Taking what we learned about the risks of the pairwise model, we can design a more sophisticated one that amortizes Alice's cost throughout the network route by iteratively decreasing the cost of transactions as they move through the system. Say Alice pays X with four units of micropayment, X pays Y with three units, Y pays Z with two units, and Z finally pays Bob only one unit.
- In the case of nonfungible POWs, we still lose. First of all, Alice can still make use of greater wealth, economies of scale, distributed computing, etc., in order to attack intermediate nodes. While the load decreases as it moves though the system, peers X, Y, and Z still need to devote some of their own resources; they may be unable to afford that load.
- For fungible payments, this model appears more promising. Intermediate nodes end up as net creditors: their resources are paid for by the cut they take from Alice's initial lump-sum payment.
- But this model has another weakness from a security point of view: we leak information regarding the route length. We mentioned the Mixmaster mix net at the beginning of this section; the system allows a sender to specify the number and identity of intermediate remailers. This number of hops and their corresponding identities are unknown to all other parties.[37] But if we use amortized payments, each peer in the chain has to know the amount it is given and the function used to decrease payments, so intermediate peers can extrapolate how many hops are in the route as well as their relative positions in the chain.
- Furthermore, Alice may not know the route length. If a system uses Gnutella- or Freenet-type searching, Alice has no idea how many hops are necessary before the query reaches Bob.
- As Alice's query branches out through the network, payments could become prohibitively expensive. For example, in Gnutella, we can estimate the number of nodes that a query traverses by treating the network as a binary tree rooted at the originating node, where the query traverses the first k levels (k is the query's time-to-live (TTL)). This gives a total of 2k+1-1 nodes visited by the query--and all of these nodes want to be paid. Thus the amount of nodes to pay is exponential in the TTL. Indeed, in reality the branching factor for the tree will be much greater than 2, leading to even more nodes that need payment. Freenet searching may be much more efficient; for more details, see Chapter 14.
- All points model
- These previous problems lead us to settle on an all points model. Alice pays each peer engaged in the protocol, intermediate and endpoint alike. Of course, we immediately run into the same problem we had in the previous model, where Alice may not know which peers are involved, especially during a search. But let's assume for this discussion that she knows which nodes she'll be using.
- This solution is ideal for such fully identified systems. The cost of resource use falls solely upon its instigating requestor.
- Anonymous systems add a few difficulties to using this model. First of all, we lose some of our capacity to use interactive payment models. For the forward-only Mixmaster mix net, intermediate nodes cannot tell Alice what client puzzle she should solve for them because only the first hop knows Alice's identity. Therefore, payments must be of a noninteractive variety.
- To stop double-spending, the scheme must use either a centralized bank server model (such as Chaumian e-cash) or have recipient-specific information encoded in the payment (such as hash cash). This recipient-specific information should further be hidden from view, so as to protect an eavesdropper from being able to piece together the route by looking at the micropayments. Recipient-hiding cryptosystems[38] help ensure that the act of encrypting the micropayment does not itself leak information about to whom the data is encrypted.
- In short, the all points payment model--while offering advantages over the prior three models--presents its own difficulties.
Micropayment schemes can help ensure accountability and resource allocation in peer-to-peer systems. But the solution requires careful design and a consideration of all security problems: there are no simple, off-the-shelf solutions.
Micropayments in the Free Haven context
Most Free Haven communication is done by broadcast. Every document request or reputation referral is sent to every other Free Haven server. Even if we can solve the micropayments issue for mix nets as described above, we still need to ease the burden of multiple payments incurred by each server each time it sends even a single Free Haven broadcast.
The first step is to remember that our communications channel already has significant latency. Nobody will care if we introduce a little bit more. We can queue the broadcasts and send a batch of them out every so often--perhaps once an hour. This approach makes the problem of direct flooding less of a problem, because no matter how many broadcasts we do in the system, our overall use of the mix net by the n Free Haven servers is limited to n2 messages per hour. We assume that the size of the message does not dramatically increase as we add more broadcasts to the batch; given that each Free Haven communication is very small, and given the padding already present in the mix net protocol, this seems like a reasonable assumption.
However, batching helps the situation only a little. For several reasons--the lack of a widely deployed electronic cash system, our desire to provide more frictionless access regardless of wealth, and the complex, central-server model used by most fungible payment systems to issue coins--nonfungible POW micropayments are better suited for Free Haven. Likewise, nonfungible payments work best with the expensive all-points payment scheme. We still have the problem, therefore, that every server must pay each intermediate node used to contact every other server each hour.
It is conceivable that spreading the waste of time for each message over the hour would produce a light enough load. Servers could simply do the computation with idle cycles and send out a batch of broadcasts whenever enough calculations have been performed.
We can solve this more directly by thinking of the server Alice as a mailing list that uses pay-per-send email as described earlier in this chapter, in the section "Nonfungible micropayments." In this case, users attach special tickets to messages sent to Alice, so they don't have to perform a timewasting computation. Similarly, we might be able to introduce into the mix net protocol a "one free message per hour" exception. But making this exception introduces a difficult new problem--our primary purpose is to maintain the anonymity of the senders and recipients through the mix net, but at the same time we want to limit each server to sending only one message per recipient in each hour. Thus, it seems that we need to track the endpoints of each message in order to keep count of who sent what.
Having Alice distribute blinded tickets as an end-to-end solution doesn't work easily either, as these tickets are used with the intermediate mix net nodes. The tickets would need to assure the nodes of both Alice's identity as a Free Haven server and her certification of the user's right to mail her, while still maintaining the pseudonymity of both parties.
The alternative is to have node-specific tickets for our all points model. More precisely, each mix net node issues a limited number of blinded tickets for each hour and user. This design also adds the functionality of a prepaid payment system, if we want one. Project Anon, an anonymous communications project, suggests such a technique.[39] It's important to note that most blind signature techniques use interactive protocols, which are less suitable for our type of application.
Introducing a free message every hour to the mix net protocol also allows for smooth integration of another Free Haven feature: we want to allow anonymous users to proxy a document retrieve request through certain (public) Free Haven servers. Specifically, a user generates a one-time mix net reply block and a one-time key pair and passes these to a Free Haven node along with a handle to the document being requested. This Free Haven node broadcasts the query to all other servers, just as in a normal retrieve operation. Because bundling extra broadcasts into each hourly message is virtually free, we can allow these extra anonymous requests without much extra cost. Of course, a concerted flood of document requests onto a server could cause its hourly message to be very large; public Free Haven servers may have to drop document requests after a certain threshold or find some other mechanism for limiting this threat of flooding.
Overall, providing bandwidth accountability along with anonymity is a tough problem. What we describe above does not provide any clear solution for an environment in which we want to maintain strong anonymity. This discussion may help to explain why current mix net implementations don't use micropayments to address accountability. Further research is certainly necessary.
Reputation systems
The Free Haven reputation solution has two parts: first, we need to notice servers that drop data early, and second, we need to develop a process for "punishing" these servers.
It's very difficult to notice if a server drops data early, and we still haven't solved the problem completely. The buddy system laid out in Chapter 12 is our current approach, and it may well be good enough. After all, we simply have to provide a system that is difficult to reliably fool--it doesn't have to catch every single instance of misbehavior.
As for punishing misbehaving servers, that's where our reputation scheme comes in. The first step in developing a solution that uses reputation systems is to examine the situation more thoroughly and try to understand our goals and limitations. Every situation contains features that make it hard to develop a reputation solution and features that make it easier.
We expect the Free Haven domain to include a number of generous individuals who will take some risks with their reputations and resources. Since disk space is very cheap and getting cheaper, and there's no significant loss if a single trade goes bad, the Free Haven environment is relatively lenient.
Ratings in the reputation system are tied to transactions and include digitally signed receipts. So we can be pretty certain that either a given transaction actually did happen, or the two parties are conspiring. At regular intervals, each Free Haven server broadcasts a "reputation referral," a package of ratings of other servers. Nodes should broadcast reputation referrals in several circumstances:
- When they log the honest completion of a trade
- When they check to see if a buddy to a share they hold is still available and find that it is missing
- When there's a substantial change in the reputation or credibility of a given server, compared to the last reputation referral about that server
How often to broadcast a referral can be a choice made by each server. Sending referrals more often allows that server to more easily distribute its current information and opinions to other servers in the network. On the other hand, frequent broadcasts use more bandwidth, and other servers may ignore servers that talk too much.
Servers get most of their information from their own transactions and trades. After all, those are the data points that they are most certain they can trust. Each server keeps its own separate database of information that it knows, based on information it has observed locally and information that has come to it. Thus every server can have a different view of the universe and a different impression of which servers are reputable and which aren't. Indeed, these local decisions introduce a lot of flexibility into the design: Each server operator can choose her own thresholds for trust, broadcast frequency, which trades are accepted or offered, etc. These decisions can be made to suit her particular situation, based, for instance, on available bandwidth and storage or the expected amount of time that she'll be running a Free Haven server.
Since each server is collecting referrals from other servers (and some of those servers may be trying to discredit good servers or disrupt the system in other ways), we need a robust algorithm for combining the referrals. Each server operator can use an entirely separate algorithm, but realistically speaking, most of them will use a default configuration recommended by the Free Haven designers.
Some ways of choosing a good algorithm are described earlier in this chapter, in the section "Scoring systems." In Free Haven, we don't expect to have to focus on very many parameters in order to get a reasonable score. Our basic approach to developing a score for a given server is to iterate through each rating available on that server and weight each rating based on how important and relevant it appears to be. Parameters that we might want to examine while weighting a score include the following:
- How recent is this rating?
- Newer ratings should get more weight.
- How similar (in terms of size and expiration date) is this rating to the transaction I'm currently considering?
- Similar ratings should get more weight.
- In my experience, has this server accurately predicted the behavior that I have observed?
- This deals with the credibility of the rater.
- How often does the server send referrals?
- If a server is verbose, we might choose to assign a lower weight to each rating. On the other hand, if this is the first referral we've ever gotten from this server, we might regard it with skepticism.
- How long has the rating server been a Free Haven server?
- We will probably have greater confidence in servers that have been part of the system for a long time.
As explained in Chapter 12, each server needs to keep two values to describe each other server it knows about: reputation and credibility. Reputation signifies a belief that the server in question will obey the Free Haven Protocol. Credibility represents a belief that the referrals from that server are valuable information. For each of these two values, each server also needs to maintain a confidence rating. This indicates how firmly the server believes in these values, and indicates how much a value might move when a new rating comes in.
When new servers want to join the system, they must contact certain servers that are acting as introducers. These introducers are servers that are willing to advertise their existence in order to introduce new servers to the rest of the servnet. Introducing consists simply of broadcasting a reputation referral with some initial reputation values. Each introducer can of course choose her own initial values, but considering the discussion in the section "Problems with pseudospoofing and possible defenses," earlier in this chapter, it seems most reasonable to broadcast an initial referral value of zero for both reputation and credibility.
At first glance, it seems that we do not need to worry about information leaks from the compiled scores--after all, the entire goal of the system is to communicate as much information as possible about the behavior history of each pseudonym (server). But a closer examination indicates that a large group of ratings might reveal some interesting attributes about a given server. For instance, by looking at the frequency and quantity of transactions, we might be able to learn that a given server has a relatively large hard drive. We currently believe that leaking this type of information is acceptable.
Other considerations from the case study
Alice has paid for some resource. But did she get what she paid for? This question deals with the problem of trust, discussed more fully in Chapter 15. But given our discussion so far, we should note a few issues that apply to various distributed systems.
In the case of data storage, at a later date, Alice can query Bob for her document and verify its checksum in order to be sure Bob has properly stored her document. She cannot be sure Bob has answered all requests for that document, but she may be more convinced if Bob can't determine that she's the one doing the query.
A distributed computation system can check the accuracy of the results returned by each end user. As we saw earlier in this chapter, some problems take a lot longer to solve than a checker takes to verify the answer. In other situations, we can use special algorithms to check the validity of aggregate data much faster than performing each calculation individually. For example, there are special batch verification methods for verifying many digital signatures at once that run much faster than checking each signature individually.[40] On the other hand, sometimes these schemes leave themselves open to attack.[41]
The methods we've described take advantage of particular properties of the problem at hand. Not all problems are known to have these properties. For example, the SETI@home project would benefit from some quick method of checking correctness of its clients. This is because malicious clients have tried to disrupt the SETI@home project in the past. Unfortunately, no quick, practical methods for checking SETI@home computations are currently known.[42]
Verifying bandwidth allocation can be a trickier issue. Bandwidth often goes hand-in-hand with data storage. For instance, Bob might host a web page for Alice, but is he always responding to requests? A starting point for verification is to sample anonymously at random and gain some statistical assurance that Bob's server is up. Still, the Mixmaster problem returns to haunt us. David Chaum, who proposed mix nets in 1981,[43] suggested that mix nodes publish the outgoing batch of messages. Alternatively, they could publish some number per message, selected at random by Alice and known only to her. This suggestion works well for a theoretical mix net endowed with a public bulletin board, but in Internet systems, it is difficult to ensure that the mix node actually sends out these messages. Even a bulletin board could be tampered with.
Above, we have described some approaches to addressing accountability in Free Haven. We can protect against bandwidth flooding through the use of micropayments in the mix net that Free Haven uses for communication, and against data flooding through the use of a reputation system. While the exact details of these proposed solutions are not described here, hopefully the techniques described to choose each accountability solution will be useful in the development of similar peer-to-peer publication or storage systems.
Conclusion
Now we've seen a range of responses to the accountability problem. How can we tell which ones are best? We can certainly start making some judgments, but how does one know when one technique is better suited than another?
Peer-to-peer remains a fuzzy concept. A strict definition has yet to be accepted, and the term covers a wide array of systems that are only loosely related (such as the ones in this book). This makes hard and fast answers to these questions very difficult. When one describes operating systems or databases, there are accepted design criteria that all enterprise systems should fulfill, such as security and fault tolerance. In contrast, the criteria for peer-to-peer systems can differ widely for various distributed application architectures: file sharing, computation, instant messaging, intelligent searching, and so on.
Still, we can describe some general themes. This chapter has covered the theme of accountability. Our classification has largely focused on two key issues:
- Restricting access and protecting from attack
- Selecting favored users
Dealing with resource allocation and accountability problems is a fundamental part of designing any system that must serve many users. Systems that do not deal with these problems have found and will continue to find themselves in trouble, especially as adversaries find ways to make such problems glaringly apparent.
With all the peer-to-peer hype over the past year--which will probably be spurred on by the publication of this book--we want to note a simple fact: peer-to-peer won't save you from dealing with resource allocation problems.
Two examples of resource allocation problems are the Slashdot effect and distributed denial of service attacks. From these examples, it's tempting to think that somehow being peer-to-peer will save a system from thinking about such problems--after all, there's no longer any central point to attack or flood!
That's why we began the chapter talking about Napster and Gnutella. Unfortunately, as can be seen in Gnutella's scaling problems, the massive amounts of Napster traffic, and flooding attacks on file storage services, being peer-to-peer doesn't make the problems go away. It just makes the problems different. Indeed, it often makes the problems harder to solve, because with peer-to-peer there might be no central command or central store of data.
The history of cryptography provides a cautionary tale here. System designers have realized the limits of theoretical cryptography for providing practical security. Cryptography is not pixie dust to spread liberally and without regard over network protocols, hoping to magically achieve protection from adversaries. Buffer overflow attacks and unsalted dictionary passwords are only two examples of easy exploits. A system is only as secure as its weakest link.
The same assertion holds for decentralized peer-to-peer systems. A range of techniques exists for solving accountability and resource allocation problems. Particularly powerful are reputation and micropayment techniques, which allow a system to collect and leverage local information about its users. Which techniques should be used depends on the system being designed.
Acknowledgments
First and foremost, we'd like to thank our editor, Andy Oram, for helping us to make all of these sections fit together and make sense. Without him, this would still be just a jumble of really neat ideas. We would also like to thank a number of others for reviews and comments: Robert Zeithammer for economic discussion of micropayments, Jean-François Raymond and Stefan Brands for micropayments, Nick Mathewson and Blake Meike for the reputations section, and Daniel Freedman, Marc Waldman, Susan Born, and Theo Hong for overall edits and comments.
1. Garrett Hardin (1968), "The Tragedy of the Commons," Science 162, pp. 1243-1248.
2. Mancur Olson (1982), "The Logic of Collective Action." In Brian Barry and Russell Hardin, eds., Rational Man and Irrational Society. Beverly Hills, CA: Sage, p. 44.
3. A pseudonymous identity allows other participants to link together some or all the activities a person does on the system, without being able to determine who the person is in real life. Pseudonymity is explored later in this chapter and in Chapter 12.
4. In retrospect, the Internet appears not to be an ideal medium for anonymous communication and publishing. Internet services and protocols make both passive sniffing and active attack too easy. For instance, email headers include the routing paths of email messages, including DNS hostnames and IP addresses. Web browsers normally display user IP addresses; cookies on a client's browser may be used to store persistent user information. Commonly used online chat applications such as ICQ and Instant Messenger also divulge IP addresses. Network cards in promiscuous mode can read all data flowing through the local Ethernet. With all these possibilities, telephony or dedicated lines might be better suited for this goal of privacy protection. However, the ubiquitous nature of the Internet has made it the only practical consideration for digital transactions across a wide area, like the applications discussed in this book.
5. Lance Cottrell (1995) "Mixmaster and Remailer Attacks," http://www.obscura.com/~loki/remailer/remailer-essay.html.
6. "Electronic Frontiers Georgia List of Public Mixmaster Remailers," http://anon.efga.org/Remailers.
7. Cynthia Dwork and Moni Naor (1993), "Pricing via Processing or Combating Junk Mail," in Ernest F. Brickell, ed., Advances in Cryptology-- Crypto '92, vol. 740 of Lecture Notes in Computer Science, pp. 139-147. Springer-Verlag,16-20 August 1992.
8. Adam Back, "Hash Cash: A Partial Hash Collision Based Postage Scheme," http://www.cypherspace.org/~adam/hashcash.
9. A. Juels and J. Brainard, "Client Puzzles: A Cryptographic Defense Against Connection Depletion Attacks," NDSS '99.
10. "RSA Laboratories Unveils Innovative Countermeasure to Recent `Denial of Service' Hacker Attacks," press release, http://www.rsasecurity.com/news/pr/000211.html.
11. For example, by breaking a puzzle into eight subpuzzles, you can increase the amount of average work required to solve the puzzle by the same amount as if you left the puzzle whole but increased the size by three bits. However, breaking up the puzzle is much better in terms of making it harder to guess. The chance of correctly guessing the subpuzzle version is 2-8k, while the chance of guessing the larger single version is just 2-(k+3), achieved by hashing randomly selected inputs to find a collision without performing a brute-force search.
12. Ronald L. Rivest, Adi Shamir, and David A. Wagner (1996), "Time-Lock Puzzles and Timed-Release Crypto."
13. Historical note: NC stands for Nick's Class, named after Nicholas Pippenger, one of the first researchers to investigate such problems. For more information, see Raymond Greenlaw, H. James Hoover, and Walter L. Ruzzo (1995), Limits to Parallel Computation: P-Completeness Theory. Oxford University Press.
14. Eytan Adar and Bernardo A. Huberman, "Free Riding on Gnutella." Xerox Palo Alto Research Center, http://www.parc.xerox.com/istl/groups/iea/papers/gnutella.
15. "DigiCash Loses U.S. Toehold," CNET news article, http://www.canada.cnet.com/news/0-1003-200-332852.html.
16. R. Rivest and A. Shamir (1997), "PayWord and MicroMint: Two Simple Micropayment Schemes," Lecture Notes in Computer Science, vol. 1189, Proc. Security Protocols Workshop, Springer-Verlag, pp. 69-87.
17. Given a hash function with an n-bit output (e.g., for SHA-1, n=160), we must hash approximately 2n(k-1)/k random strings in order to find a k-way collision. This follows from the "birthday paradox" as explained in Rivest and Shamir, ibid.
18. Markus Jakobsson and Ari Juels (1999), "Proofs and Work and Bread Pudding Protocols." In B. Preneel, ed., Communications and Multimedia Security. Kluwer Academic Publishers, pp. 258-272.
19. D. Chaum (1983), "Blind Signatures for Untraceable Payments," Advances in Cryptology--Crypto '82, Springer-Verlag, pp. 199-203. D. Chaum (1985), "Security Without Identification: Transaction Systems to Make Big Brother Obsolete," Communications of the ACM, vol. 28, no. 10, pp. 1030-1044. D. Chaum, A. Fiat, and M. Naor (1988), "Untraceable Electronic Cash," Advances in Cryptology--Crypto '88, Lecture Notes in Computer Science, no. 403, Springer-Verlag, pp. 319-327. D. Chaum (August 1992), "Achieving Electronic Privacy" (invited), Scientific American, pp. 96-101, http://www.chaum.com/articles/Achieving_Electronic_Privacy.htm.
20. Stefan Brands (1993), "Untraceable Off-Line Cash in Wallet with Observers," Advances in Cryptology--Crypto '93, Lecture Notes in Computer Science, no. 773, Springer-Verlag, pp. 302-318. Stefan Brands (2000), Rethinking Public Key Infrastructures and Digital Certificates: Building in Privacy. MIT Press. Stefan Brands, online book chapter from Rethinking Public Key Infrastructures and Digital Certificates: Building in Privacy, http://www.xs4all.nl/~brands/cash.html.
21. Arsene Jules Etienne Dupuit (1842), "On Tolls and Transport Charges," Annales des Ponts et Chaussees, trans. 1962, IEP.
22. P. C. Fishburn and A. M. Odlyzko (1999), "Competitive Pricing of Information Goods: Subscription Pricing Versus Pay-Per-Use," Economic Theory, vol. 13, pp. 447-470, http://www.research.att.com/~amo/doc/competitive.pricing.ps. Y. Bakos and E. Brynjolfsson (December 1999), "Bundling Information Goods: Pricing, Profits, and Efficiency," Management Science, http://www.stern.nyu.edu/~bakos/big.pdf.
23. Sun Security Bulletin 198, "Revocation of Sun Microsystems Browser Certificates," "How to Detect or Remove the Invalid Certificate," http://sunsolve5.sun.com/secbull/certificate_ howto.html. Computer Emergency Response Team Bulletin CA-2000-19, http://www.cert.org/advisories/CA-2000-19.html.
24. Neal McBurnett, "PGP Web of Trust Statistics," http://bcn.boulder.co.us/~neal/pgpstat.
25. Thawte, "Personal Certificates for Web and Mail: The Web of Trust," http://www.thawte.com/certs/personal/wot/about.html.
26. Yinan Yang, Lawrie Brown, and Jan Newmarch, "Issues of Trust in Digital Signature Certificates," http://www.cs.adfa.oz.au/~yany97/auug98.html.
27. Rohit Khare and Adam Rifkin, "Weaving a Web of Trust," http://www.cs.caltech.edu/~adam/papers/trust.html.
28. Raph Levien, "Advogato's Trust Metric," http://www.advogato.org/trust-metric.html.
29. Thomas H. Cormen, Charles E. Leiserson, and Ronald L. Rivest, Introduction to Algorithms (MIT Press and McGraw-Hill, Cambridge, MA, 1990).
30. "eBay, Authorities Probe Fraud Allegations," CNET news article, http://www.canada.cnet.com/news/0-1007-200-1592233.html.
31. David D. Kirkpatrick, "Book Agent's Buying Fuels Concern on Influencing Best-Seller Lists," New York Times Abstracts, 08/23/2000, Section C, p. 1, col. 2, c. 2000, New York Times Company.
32. "eBay Feedback Removal Policy," http://pages.ebay.com/help/community/fbremove.html.
33. D. Chaum (1981), "Untraceable Electronic Mail, Return Addresses, and Digital Pseudonyms." Communications of the ACM, vol. 24, no. 2, pp.84-88.
34. "Electronic Frontiers Georgia Remailer Uptime List," http://anon.efga.org.
35. Tal Malkin (1999), MIT Ph.D. thesis, "Private Information Retrieval and Oblivious Transfer."
36. Masayuki Abe (1998), "Universally Verifiable MIX-Network with Verification Work Independent of the Number of MIX Servers," EUROCRYPT '98, Springer-Verlag LNCS.
37. We ignore the possibility of traffic analysis here and assume that the user chooses more than one hop.
38. David Hopwood, "Recipient-Hiding Blinded Public-Key Encryption," draft manuscript.
39. Oliver Berthold, Hannes Federrath, and Marit Köhntopp (2000), "Anonymity and Unobservability in the Internet," Workshop on Freedom and Privacy by Design/Conference on Computers, Freedom and Privacy 2000, Toronto, Canada, April 4-7.
40. Mihir Bellare, Juan A. Garay, and Tal Rabin (1998), "Fast Batch Verification for Modular Exponentiation and Digital Signatures," EUROCRYPT '98, pp. 236-250.
41. Colin Boyd and Chris Pavlovski (2000), "Attacking and Repairing Batch Verification Schemes," ASIACRYPT 2000.
42. David Molnar (September 2000), "The SETI@home Problem," ACM Crossroads, http://www.acm.org/crossroads/columns/onpatrol/september2000.html.
43. D. Chaum, "Untraceable Electronic Mail, Return Addresses, and Digital Pseudonyms," op. cit.